Our data science team is ready to help you with your problems, no matter how complex they might seem. We apply our know-how to a large variety of contexts, from computer vision for predictive maintenance to timeseries prediction and classification for facility management to causal inference for identifying failure sources.
We are always on top of the state-of-the-art machine learning techniques, and follow the most important conferences of the field, like ICML, ICLR and NeurIPS. This means that we do not only apply machine learning models as a black box, but we do not hesitate to adapt them to your needs and deliver customized solutions and Artificial Intelligence (AI).
Our lean way of applying data science ensures that your costs will be minimal regardless of the size of the project. We work on the cloud, but also on premises, so if you do not have a data science infrastructure, we can help you with that.

Computer vision is one of the machine learning fields that evolved the most in the last few years, thanks to new advances in optimization. At the same time, lower hardware costs and higher computational power (using GPUs) has enabled problems that were unimaginable a few years ago to be solved in seconds today.
Using deep learning models, like convolutional neural networks (CNNs), we can solve problems like image segmentation, object recognition or object detection. The analysis can be thus in low level in the pixel size, or on a high level on object or image size.
By using GPU computing on the cloud, we minimize costs and maximize computation speed. We work with open source software, so you do not have to worry about expensive licensing running costs.
Deep learning is not only used for imaging. Recurrent neural networks (RNNs, LSTMs, GRUs, …) have changed the way we analyze timeseries today. We no longer speak about frequency analysis, but about pattern recognition, classification, and prediction.
With hundreds of billions of sensors in the world, timeseries data is huge today. In LeanBI we have worked in various predictive maintenance and analytics projects, with different types of timeseries. Vibration, voltage or rotation speed readings, anything that can be measured periodically can help detect and identify problems early, or even predict future system behavior.

When we are searching for failures, it is often the case that we do not have many previous examples (labels). Then, classification techniques cannot be applied, as we do not have enough data to model all problematic cases.
Anomaly detection, luckily, does not need labels: it is unsupervised. By modeling what is considered “normal behavior”, we can classify anything different as an anomaly.
Anomaly detection is often used in predictive maintenance, but also in any scenario where we do not know what to expect to go wrong. In LeanBI, we have applied our expertise in anomaly detection in all types of data, whether it is visual, timeseries, or structured features.
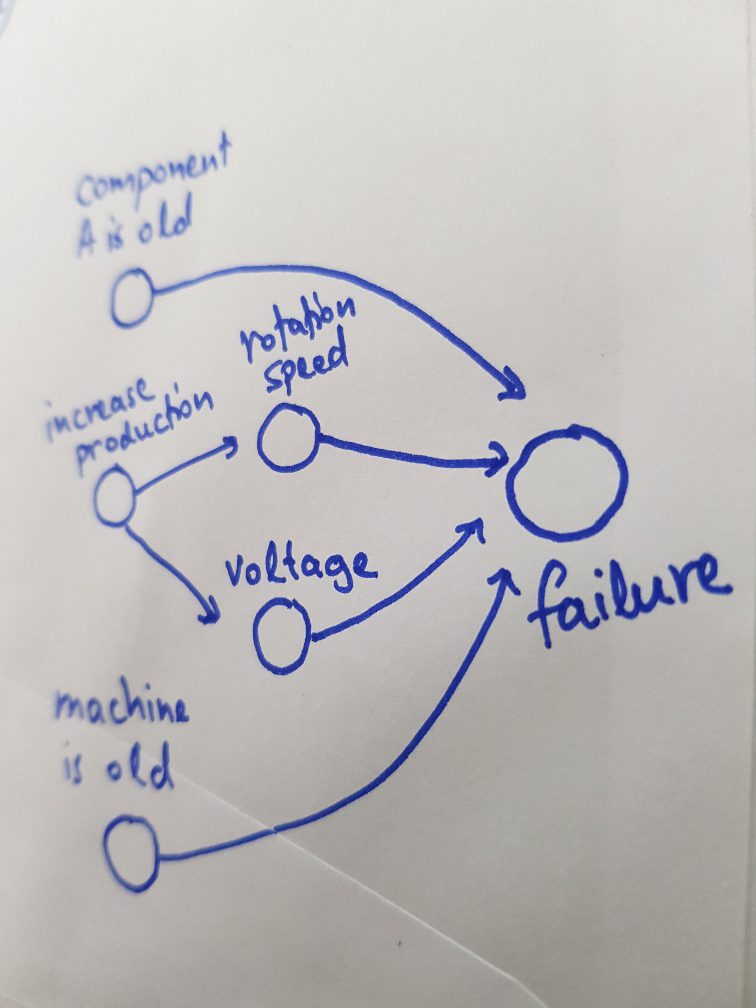
Two questions that we often hear from our clients are “how can we use our domain know-how to make the model smarter?” and “how are we going to get so much data needed by deep-learning?”
Probabilistic (Bayesian) modeling hits two birds with one stone: (1) it can incorporate domain knowledge, and therefore (2) it needs less data. Another advantage of Bayesian models is that they quantify uncertainty: when we get an answer, we also know how much we can trust it.
We can apply probabilistic modeling to most machine learning setups: classification or prediction, for image or timeseries data, and even combine them with deep learning. We can also use them for causal inference: we are searching what caused a result: “which of all potential factors was responsible for the machine’s damage?”.
In LeanBI we always strive to use the field experts know-how as much as possible in our models. Probabilistic modeling is often the right tool for this, for example using physical modeling with probability distributions to explain indoor air quality, or to quantify the probability of each potential failure in predictive maintenance.