Verständlich erklärt: Technisches Vorgehen bei Predictive Analytics am konkreten Beispiel „Lagerhaltung von Bier“
Bei Predictive Analytics werden historische und aktuelle Daten statistisch analysiert, um mit den gewonnenen Erkenntnissen Ereignisse (häufig in der Zukunft) vorauszusagen. Die Voraussagen sind statistischer Art im Stil von: Der Bierkonsum wird in Rio Anfang August 2016 mit einer Wahrscheinlichkeit von 90% um mindestens 21% ansteigen, in Bern um mindestens 25%.
Bereits heute ist Predictive Analytics im Einsatz:
- Predictive Maintenance: Der Zeitpunkt eines Produkt-Defektes wird vorausgesagt –> Die Unterhalts-Firma kann im Voraus reagieren
- Kundenzufriedenheit: Eine Firma sagt die Zufriedenheit eines Kunden voraus –> Proaktiv wird der Kunde bei seinen Problemen unterstützt –> Der Kunde bleibt hoffentlich treu
- Credit Scoring: Die Bank schätzt die Wahrscheinlichkeit ein, ob ein Schuldner einen Kredit rechtzeitig zurückzahlt –> Entscheidung ob der Kredit gewährt wird
- Predictive Police: In Zürich werden Einbrüche vorhergesagt –> Polizei zielgerichtet einsetzen
Ein erfolgreiches Predictive Analytics Projekt besteht aus drei Key Elementen, wobei wir uns in diesem Blog auf die technische Umsetzung konzentrieren.
- Zugriff auf relevante Daten
- Eine Frage, die mit Hilfe der Daten zu beantworten ist.
- Eine technische Umsetzung mit Algorithmen und Modellen
Übersicht des Vorgehens
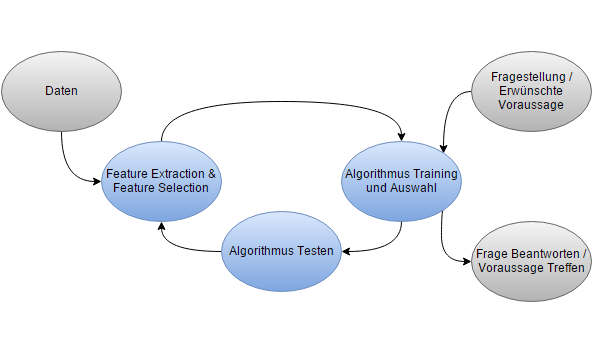
Bild: Vorgehensprozess Predictive Analytics
Die Daten durchlaufen die Prozesse Feature Extraction und Feature Selection (deutsch: Merkmals-Extraktion & Merkmals-Auswahl) Hier wird im Wesentlichen entschieden, wie eine gewisse Information weiterverarbeitet soll, bevor sie verwendet wird (Feature Extraction) und welche Information aus den vorhandenen Daten überhaupt verwendet werden sollen (Feature Selection). Die so gewonnenen und ausgewählten Features (Datenmerkmale) durchlaufen dann einen Algorithmus. Der Algorithmus wird antrainiert, indem bestehende Ergebnisdaten aus der Vergangenheit verwendet werden. Es findet danach, wie im Bild dargestellt, eine schrittweise Optimierung statt, indem bessere Features bereitgestellt oder Features gelöscht werden, welche dem Algorithmus nicht weitergeholfen haben. Auch werden unterschiedliche Algorithmen getestet, bis eine zufriedenstellende Voraussage besteht. Dann wird der beste trainierte Algorithmus eingesetzt, um mit neuen Daten qualitativ hochwertige Voraussagen zu liefern.
Wir gehen nun detaillierter auf die verschiedenen Punkte ein.
Feature Extraction
Aus einem Datum können beispielsweise viele Informationen gewonnen werden: Wochentag, Wochenende, Schulferien, findet gerade die Olympiade statt, steht der 1. August vor der Tür. Alles Informationen, welche je nach Fragestellung sehr hilfreich sind: Wochenende -> Mehr Zeit zum Trinken, 1. August -> Grosser Detailhandelumsatz am Tag davor, Olympiade -> Grosse Biernachfrage, usw.. So kann Feature Extraction entscheidend dazu beitragen, dass ein Algorithmus die Biernachfrage gut voraussagen kann.
Feature Selection
Auch die Auswahl der Datenmerkmale (Feature Selection) ist ein wichtiger Teil. Es gibt bekanntlich eine Fülle an verschiedenen Daten. Es ist unklug, alle vorhandenen Daten dem Algorithmus zur Verfügung zu stellen, da dies sonst zu einem sogenannten Overfitting (deutsch Überanpassungs-Problem) führen kann. Dass am 23. November 2015 der Berner Zibelemärit stattfand, beeinflusste den Glühweinkonsum gewaltig, bringt uns aber in der richtigen Bierkonsum-Vorhersage nicht weiter, es führt eher zu „Verwirrung“ und der Algorithmus muss nun zusätzlich lernen, dass er diese Information besser ignoriert. Es kann passieren, dass der Algorithmus gewisse unwichtige Datenmerkmale zu stark gewichtet, und so suboptimale Voraussagen liefern wird.
Eine Frage der Datenmenge
Man kann dem Computer die Aufgabe der Feature Extraction und Feature Selection vollständig übertragen. Das funktioniert ohne menschlichen Einfluss, wenn die Datenmenge gross genug und genügend Rechenkapazität vorhanden ist. Dann findet ein Algorithmus problemlos heraus, dass die letzten Olympischen Sommerspiele in London den Bierkonsum ankurbelten und dass dies kein Einzelfall war (auch die früheren Olympiaden führten zu einem erhöhten Bierkonsum). So kann ein Computer selbständig und ohne menschliche Interaktion das Feature „Olympische Spiele“ finden. Selbstredend funktioniert dies nur, wenn die Daten über den Zeitraum der letzten paar Olympischen Sommerspiele (15-20 Jahre) auch vorhanden sind. Dies bedingt eine genügende Datengrundlage (meistens Big Data) und einhergehend grosse Rechenleistungen (bis hin zu Datencentern wie Google). Mit grossen Datenmengen und hoher Rechenleistung verliert Overfitting an Brisanz.
Hat man die grosse Rechenpower oder die benötigten Datenmengen nicht zur Verfügung, so müssen zumindest Teile der Merkmalsbearbeitung vom Menschen erledigt werden (aber möglichst nicht am 1. August). Ein Hilfsmittel zur Anwendung der richtigen Features ist die Visualisierung der Daten. Die Visualisierungen bringen neue Einsichten und ein Verständnis der Daten, und sie können auch Indizien liefern, ob ein Zusammenhang zwischen einem Feature und der benötigten Voraussage besteht. Konkret könnte man ein mögliches Feature gegen die gewünschte Vorhersage plotten. (Beispielsweise Bierkonsum versus Bier-Produktion). Dann wird man feststellen, dass die Bier-Produktion im 7-Tage-Rhythmus zum Bierkonsum auseinanderdriftet, da am Wochenende wenig produziert und gleichzeitig mehr konsumiert wird. Und so wird ein guter Data Scientist vorschlagen, das Wochenende als Feature zu wählen.
Zielführend für mittelgrosse Projekte ist eine Kombination von menschlicher und automatischer Feature Extraction und Feature Selection. Wenn der Mensch viele wichtige aber auch unwichtige und „verwirrende“ Features erkennt, erleichtert dies dem Computer die Arbeit. Die verbleibenden Features kann nun der Algorithmus selber erkennen. Durch die moderatere Anzahl der automatisierten Merkmalsbearbeitung reduzieren sich der Rechenaufwand und die Gefahr von Overfitting.
Machine Learning Algorithmen trainieren und auswählen
Die Daten und die ausgewählten Features werden nun dem Algorithmus zu Trainingszwecken übergeben. Der Algorithmus lernt nun aus der Erfahrung u.a. wie stark die vergangenen Olympischen Sommerspiele den Bierkonsum erhöhten. So kann der Computer auch den Einfluss von Spielen auf den Bierkonsum abschätzen und am 10. August 2016 einen hohen Bierkonsum voraussagen, da gerade die Olympiade in Rio stattfindet. Dieses Lernen passiert natürlich nicht individuell auf einem Feature (der Olympiade) sondern gleichzeitig mit allen ausgewählten Features (Olympiade, Wochenende, 1. August, Fussball-WM, Oktoberfest, Wettervorhersage, Jahreszeit, Gurten-Festival usw.).
Es stellt sich nun aber die Frage, welcher Machine Learning Algorithmus verwendet werden soll. Wir stellen ein paar wichtige Anforderungen an die Algorithmen vor:
- Erforderliche Genauigkeit: Manchmal ist keine allzu genaue Voraussage erforderlich. Dann können relativ ungenaue Algorithmen eingesetzt werden, welche dafür umso schneller rechnen.
- Verfügbare Datenmengen: Bei einer kleinen Datenmenge kann nur ein Algorithmus mit wenigen Parametern verwendet werden. Mit zunehmender Datenmenge werden auch komplexere, genauere und rechenintensivere Algorithmen mit mehr Parametern möglich.
- Erklärende Algorithmen: Es kann vorkommen, dass man zusätzlich zu einer Voraussage auch noch eine Erklärung wünscht, wie die Voraussage zustande kam. Der Algorithmus soll beispielsweise mitteilen, dass die Bierkonsum-Voraussage sehr hoch ist, weil zu diesem Zeitpunkt gerade die Olympiade in Rio stattfindet. Viele Machine Learning Algorithmen sind dazu nicht im Stande.
- Eigene Algorithmen: In den häufig gebrauchten Programmen / Libraries sind nicht alle Algorithmen bereits programmiert. Der Aufwand einen Algorithmus selber zu programmieren oder eine neue Library zu verwenden kann hoch sein. Darum besteht ein gewisser Anreiz bereits vorhandene Algorithmen zu verwenden.
In der Praxis kommt es vor, dass kein Algorithmus alle Wünsche erfüllt. Insbesondere weil der „perfekte“ Algorithmus in den verwendeten Tools nicht implementiert ist. Es ist deshalb vernünftig mit einem einfachen Algorithmus zu beginnen, welcher dafür auf Knopfdruck zur Verfügung steht und schnell berechnet wird. Wenn ein solcher Algorithmus nicht annähernd eine vernünftige Voraussage liefert, ist es unwahrscheinlich, dass ein raffinierter Algorithmus eine gute Voraussage berechnet. Dann ist es zielführender, beispielsweise zusätzliche Daten und bessere Features zu verwenden. Wenn allerdings die Voraussage-Qualität eines einfachen Algorithmus noch ein wenig verbessert werden soll, können raffiniertere Algorithmen durchaus behilflich sein. So kann Schritt für Schritt nach besseren Algorithmen und Features gesucht werden.
Machine Learning Algorithmen testen
Nicht nur zum Trainieren eines Algorithmus braucht es Daten, sondern auch um den Algorithmus zu testen oder, in anderen Worten, um die Qualität eines Algorithmus zu messen. Deshalb werden die vorhandenen Daten in zwei Gruppen eingeteilt. Mit der einen Gruppe, den sogenannten Trainings-Daten, wird der Algorithmus trainiert. Mit der anderen Gruppe, den Test-Daten, wir der Algorithmus getestet. Bei einem solchen Test wird der Algorithmus beauftragt, eine gewisse Voraussage zu liefern. Die gemachte Aussage wird dann mit den realen Messungen in den Test-Daten verglichen. Der Algorithmus schneidet dann gut ab, wenn die Voraussagen gut mit den realen Messungen übereinstimmen.
Ich möchte noch ein paar Worte über die Aufteilung der Daten in Trainings- und Testdaten verlieren. Die Aufteilung sollte möglichst realistisch erfolgen, um sich beim Test nicht selber in die Irre zu locken. Beispielsweise würde ein realistischer Test für die automatische Biernachfrage entstehen, wenn man so tun würde, als ob letzter Monat wäre. Dann trainiert man den Algorithmus mit allen Daten, die vor einem Monat schon vorhanden waren. Anschliessend liefert der trainierte Algorithmus die gewünschte Voraussage der Zukunft (als von diesem Monat). Beim Test wird nun die Voraussage mit den gemessenen Werten dieses Monates verglichen.
Frage beantworten / Voraussage treffen
Nun sind die Features ausgewählt sowie der Algorithmus trainiert und so können nun die gewünschten Voraussagen maschinell geliefert werden. So weiss, beispielsweise, die Bier-Produktion wie viel sie produzieren soll. Auch die Logistik kann optimiert werden, da nun bekannt ist wo wie viel Bier nachgefragt wird. Glücklicherweise passiert die Voraussage automatisch, und so wird genügend Zeit bleiben um mit dem kühlen Lieblingsbier in der Hand die Olympiade zu schauen.
Fragen
Schreiben Sie uns bei Fragen oder Interesse an eine live Demonstration (info@leanbi.ch) oder rufen Sie uns an (+41 79 247 99 59).
- In drei Schritten zu datengestützten Produktionsverbesserungen - August 21, 2017
- Wie eine Dynamische Unternemensplanung erreicht wird - August 10, 2017
- Swiss Industry 4.0 Conference – Digitale Transformation in der Praxis - Juli 21, 2017