Am 19.11.2019 durften wir an der Predictive Maintenance Expert Group der Swiss Alliance for Data Intensive Services unsere Projekterfahrungen weitergeben. Einige dieser Erfahrungen möchten wir sehr gerne in diesem Blog teilen.
Wenn wir bei unseren Industriekunden das Thema Predictive Maintenance besprechen, ist häufig das Hauptthema die ungenügende Datenlage. «Unsere Maschinen sind so gut und produzieren kaum Fehler». Unsere Kunden sind dann voreilig der Meinung, dass Predictive Maintenance innerhalb Aufwände und Zeiten nicht umzusetzen ist. Wir wollen in diesem Blog erklären, wie wir mit diesem Thema umgehen.
Nehmen wir als Beispiel unser Predictive Maintenance Projekt in den Verteilzentren der Schweizerischen Post. In den verschiedenen Verteilzentren laufen kontinuierlich 8 Sorteranlagen mit ungefähr je 700 Kippschalen. An jedem dieser Wagen können verschiedene Defekte auftreten, was natürlich nur sehr selten passiert. Das nächste Bild zeigt hier die mögliche Defekte:
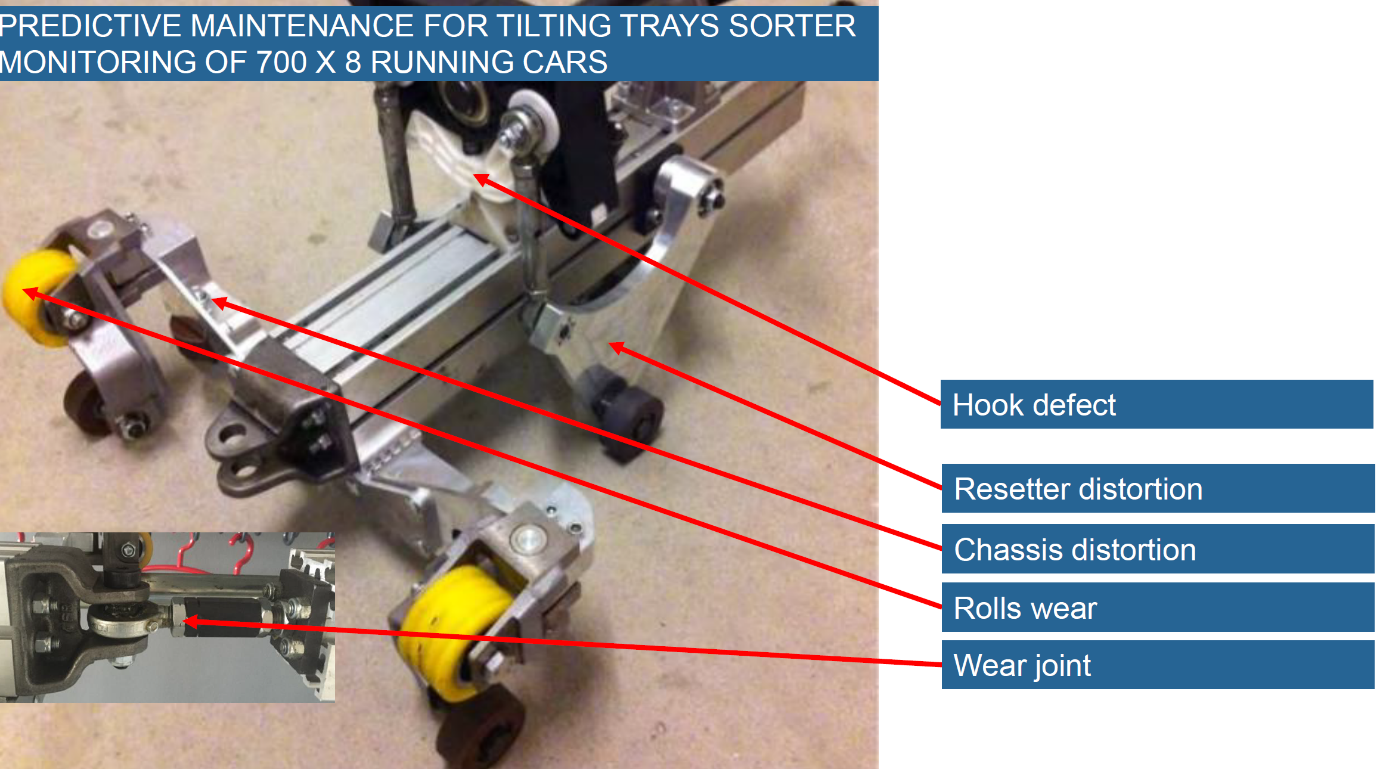
Abb. 1: Wartungsthemen am Fahrgestell eines Kippschalen- Wagens
Die folgenden Ausführungen zeigen, dass maschinelles Lernen auch dann gute Ergebnisse erzielen kann, wenn nur sehr wenige Defekte für das Training zur Verfügung stehen. Um zu erklären, wie wir das machen, einige Grundlagen:
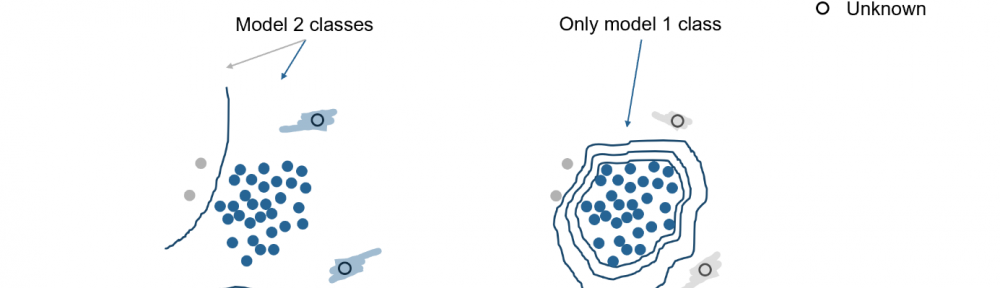
In der Abb. 2 sehen Sie das Prinzip der Klassifikation, welches zum Gebiet des Supervised Learning gehört. Wir erkennen in den 3 Bildern, dass bei ungenügender Datenlage eine ausreichende Klassifikation nicht möglich ist. Neue Messungen (im Bild mit «unknown» bezeichnet) werden im Bild ganz rechts als «normal wagon» klassifiziert, auch wenn ein Defekt am Wagen aufgetreten ist. Das Klassifikationsmodell gibt bei ungenügener Trainings-Grundlage falsche Resultate. Das passiert, wenn im Modelltraining die Datenlage nicht genügend die vorkommenden Defekte repräsentieren. In solchen Fällen wird die Lösung unbrauchbar.
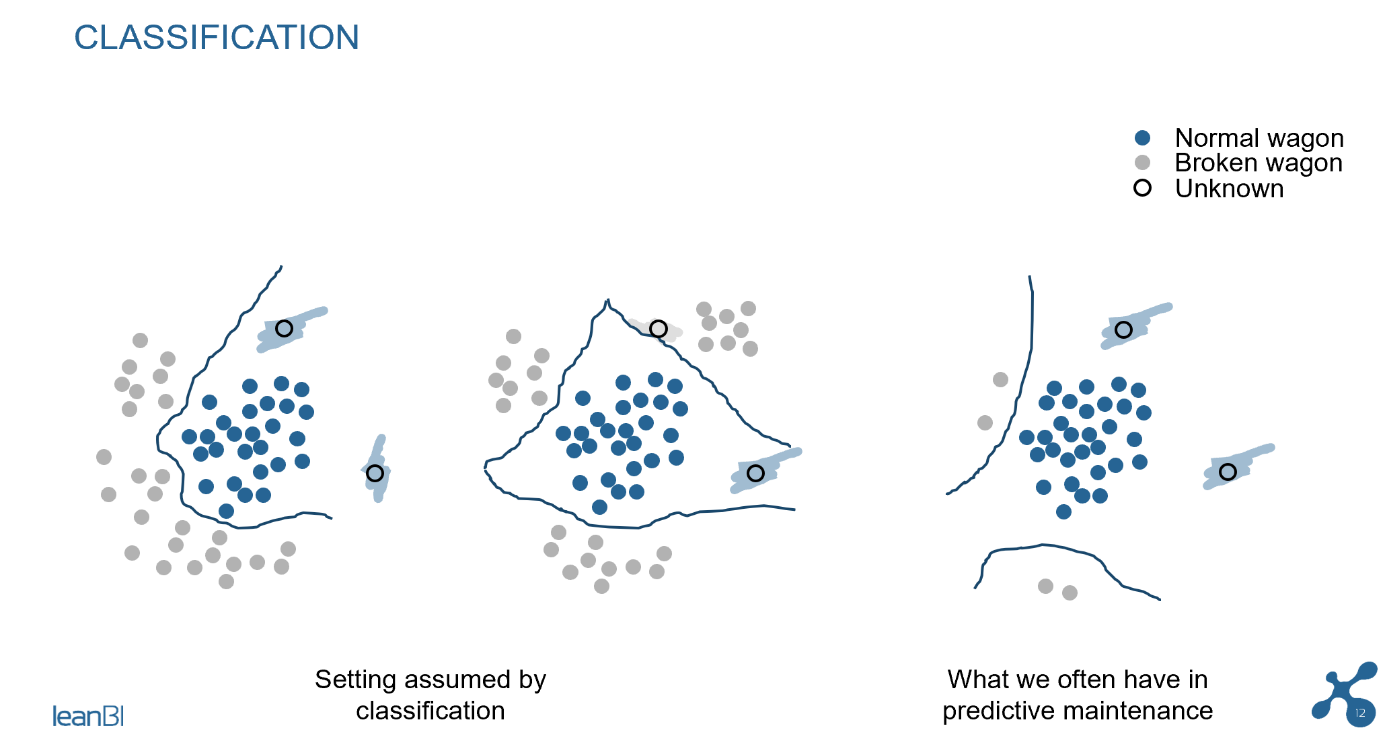
Abb. 2: Falsche Klassifikation, wenn dem Modell nur wenige Schadensfälle vorliegen
Anders sieht es bei der Anomalieerkennung aus, einer ML-Modellierung aus dem Gebiet des Unsupervised Learning. Siehe dazu das zweite Bild in Abb. 3. Während der Trainingsphase der Anomalieerkennung modellieren wir im Wesentlichen das „normale“ Verhalten der Wagen, und wir benötigen nur sehr wenige Fehlerfälle, um die Modellparameter anzupassen. Das Modell kann dann einen neuen Defekt im Feld sehr gut erkennen, da es nur die Abweichung vom Normalzustand erkennen muss, was für das Modell entsprechend einfacher ist.
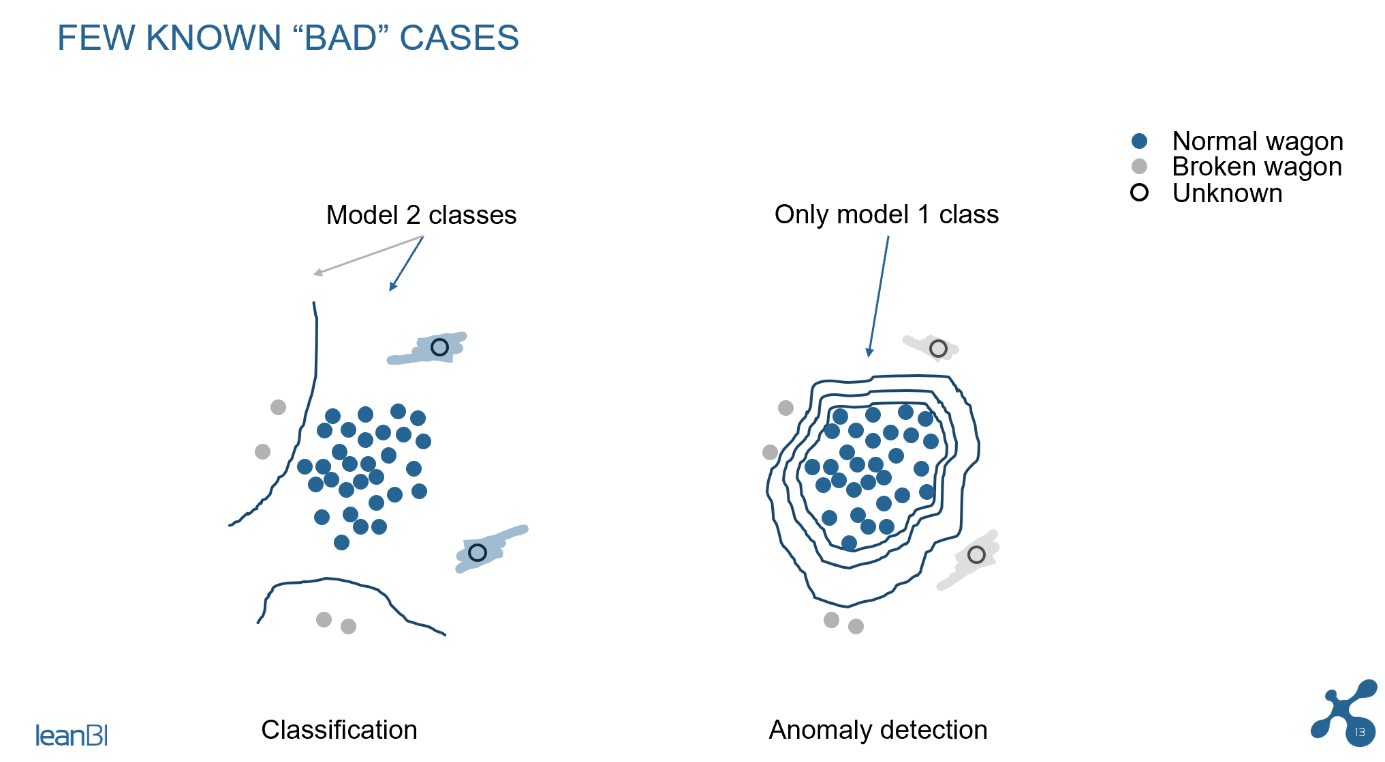
Abb. 3 Unterschied von Klassifikation und Anomalie-Erkennung
Anomalie Detektion kann noch viel mehr, was sich im Post Case anschaulich darstellen lässt. Wir messen mit einer stationären Lasertriangulation Verbiegungen an verschiedenen Teilen des Fahrgestells aus. Wir vermessen im submillimeter Bereich verschiedene Punkte und Flächen des Wagens, während dieses am Messgerät vorbeifährt. Die Auswertung deser Vermessungen geschieht innerhalb weniger Sekunden , sodass wir im Betrieb die Vermessungen an jedem Wagen online in unsere LeanBI Cloud spielen. Damit lassen sich Veränderungen über die Zeit erkennen und so mehr als nur Zustandsaussagen machen. Man sieht also frühzeitig, ob zukünftig ein Problem auftreten könnte, eine solche Information geht dann an das Wartungspersonal. Das ist Predictive Maintenance.
Die herkömmliche Meinung, dass mit der Anomalieerkennung nur eine Anomalie, aber nicht das einzelne Problem erkannt wird, stimmt nicht immer. Über das geeignete Feature Extraction, also die Auswahl der Vermessungspunkte, können wir genaue Hinweise zur Anomalie weitergeben. Also zum Beispiel die Chassis Koordinate x,y,z hat sich in der Richtung y um 0.4 mm verschoben. Das ist in diesem Fall bereits eine sehr genaue Lokalisierung des Problems.
Ein Haken muss aber noch dran sein? Ja, es ist richtig, dass die Modelle auf der Grundlage weniger Schadensbilder noch nicht sehr genau sind. Diese sind aber so genau, dass wir innterhalb einer 10% Grenze alle mögliche Schäden mitbekommen, also kein Schaden uns versehentlich durchrutscht. Es kann passieren, dass irrtümlich ein Schaden gemeldet wird, wo gar keiner ist (genannt “false positive”). Aber: Das Wartungspersonal wird 10 mal schneller als bisher, da es nur 10% der Wagen untersuchen muss. Und wir erkennen Fehler schneller (da online) und besser als das Wartungspersonal. Zum Beispiel haben bei den Testmessungen Schäden an den Wagen festgestellt, die bei den periodischen Wartungsarbeiten übersehen wurden.
In Zukunft werden wir die Modelle periodisch nachtrainieren. Damit wird dann auch diese 10%- Schwelle sinken, das Modell wird immer genauer werden.
Mit dieser Predictive Maintenance Lösung verhindern wir ungeplante Stillstände, was der Hauptnutzen eines solchen Systems ist. Denn zu Weihnachten möchten die Postkunden die Pakete rechtzeitig im Haus haben. Ungeplante Stillstände können auch sehr teuer werden, wenn ein Wagen stark beschädigt wird. Gleichzeitig reduzieren wir die Arbeit des Wartungspersonals und weisen Sie auf die konkreten Problemfelder hin. Das hilft auch bei weniger geschulten Personal.
Summa Summarum: Der Business Case für die Post Schweiz lohnt sich.
Im Bereich des Predictive Maintenance gibt es Problemfelder, die einiges komplexer als dieses Fallbeispiel sind. Kann dann die Anomalie-Erkennung scheitern? In solchen Fällen reicht zumindest die Anomalie-Erkennung alleine nicht aus. Ziel ist es, bei komplexeren Themenfelder, noch stärker das Know How der Spezialisten kontinuierlich im System einzubeziehen. Das Modell wird damit «self learning». An diesem Thema sind wir in anderen Projekten dran und werden dazu in den nächsten Blogs berichten.