L’entrepôt de données – un fardeau trop grand pour les petites et moyennes entreprises ?
À partir des années 90, le concept des entrepôts de données (Data Warehouse, ou DWH) fut développé par Immon [1] et Kimball [2], dans le but de proposer un stockage central de bonne qualité pour les données inhérentes aux entreprises. L’entrepôt de donées doit être la seule base des entreprises pour les décisions tactiques et stratégiques (Single Source of Truth). Ces concepts se sont révélés valables jusqu’à nos jours.
Différentes adaptations ont vu le jour lors de l’arrivée de nouvelles technologies. L’adaptation des technologies du BIG DATA aux modèles de données fut jusqu’à présent insuffisamment mise en œuvre. À quoi ressemble actuellement un entrepôt de données pour les petites et moyennes entreprises (PME) ? En quoi le BIG DATA peut y contribuer ? C’est de cela dont nous voulons discuter.
La construction et le fonctionnement d’un entrepôt de données se révèlent rapidement couteux pour les PME, même si des modèles de données prédéfinis et des rapports apportent un certain soulagement. D’autant plus du fait qu’un entrepôt de données comporte plusieurs couches de données avec plusieurs modèles de données. Les PME doivent-elles alors serrer les dents et accepter un entrepôt de données couteux lorsqu’elles souhaitent construire une base de données décisionnelle ? Non, car il est possible de faire autrement, à condition de savoir comment.
Il nous faut tout d’abord répondre à une question fondamentale : en quoi les PME ont-elles tout particulièrement besoin d’un entrepôt de données ? La définition de Zeh [3] nous offre ici une entrée en matière bonne et pragmatique : « Un entrepôt de données est une base de données physique, rendant possible une vision intégrée des sources de données sous-jacentes ». Le but d’un entrepôt de données se laisse ainsi simplement formuler :
- Archivage des données dans le but de pouvoir effectuer des analyses dimensionnelles, par exemple des séries chronologiques.
- Rassemblement des données à partir de différentes sources, afin d’obtenir des connaissances globales.
- Agrégation de données afin de rendre les informations plus facilement visibles et ainsi pouvoir réaliser des évaluations performantes.
Parallèlement au rapport opérationnel élaboré directement depuis les sources de données, les données sont également archivées physiquement dans un entrepôt de donées. La pratique montre que l’intégration et la modélisation de données constitue autour de 80% d’un projet décisionnel. Seulement 20% sont liés à l’investissement pour les applications frontales (le front end) comme les rapports standards et ad hoc et les tableaux de bord.
Un entrepôt de données s’alourdit rapidement avec la modélisation de données complexe et opaque inhérente à l’architecture d’un entrepôt de données conventionnel, incapable de s’accorder avec un plan technique agile en constante évolution, et encore moins avec nos approches de LeanBI. Nous nous demandons alors de quelle façon il est possible de simplifier drastiquement un entrepôt de données afin de le rendre accessible de façon optimale pour des PME à un prix abordable, tout en restant pour le client une solution de long terme de haute qualité.
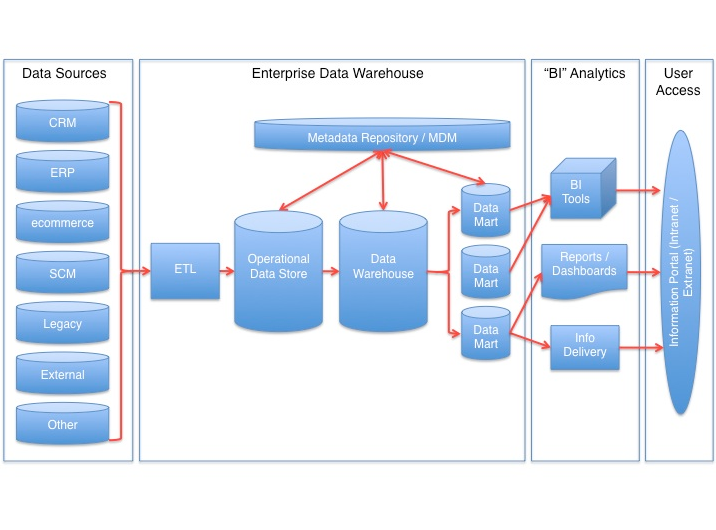
En considérant désormais les concepts d’Immon et de Kimball, il se trouve que l’approche de Kimball s’accorde bien dans notre monde agile. D’après la définition de Kimball, les « Data Marts » spécifiques (littéralement en anglais « magasins de données ») sont constitués avec des faits et des dimensions (ou axes, dans le sens de séries d’attributs de données), gérés de façon centralisée par des paramètres définis à l’avance lors de sa conception (« Conformed Dimensions »). Les dimensions contiennent toutes les données de base telles le temps, le produit, la région, le client, et beaucoup d’autres. Le Data Mart, en tant que classe sous-jacente d’un entrepôt de donées, est là pour agréger et transformer les données en une forme consistante.
D’après Kimball, un entrepôt de données est constitué à première vue d’un ensemble de Data Marts. Immon mise sur l’approche conséquente suivante : introduire une couche d’entrepôt de données dans le modèle de données normalisé 3NF (Third Normal Form), constituant la base de tous les Data Marts. L’avantage étant que les données existent alors sous une forme détaillée dans l’entrepôt de donées, de telle sorte que les demandes futures puissent être satisfaites directement par le recueil de données de l’entrepôt de données.
En principe, les deux concepts sont valables. En pratique, les deux bases ont été élaborées dans beaucoup d’entreprises ces 20 dernières années, sous la forme d’un entrepôt de données extrêmement complexe qui peine à être remplacé et menant désormais une longue et ancienne existence. La question de la simplification s’est naturellement posée. Le concept suivant trouve une large utilisation : lorsque le bon matériel est à disposition (MPP, Massive Parallel Processing), il est possible de transformer les données en un grand et unique modèle de données relationnelles.
C’est ainsi qu’on se débarrasse des Data Marts, qui apportent toujours avec eux des charges de projet et d’exploitation élevées tout en restreignant les informations. Le modèle en couche se réduit alors peu à peu (bien qu’il reste entre deux et trois couches selon le cas). La demande de performance est cependant toujours existante, notamment par l’utilisation combinée de technologies matérielles et logicielles. Globalement, les données restent librement à disposition pour une modélisation de données relativement simple.
Cet avantage a cependant un prix. Une solide gestion technique est nécessaire afin d’empêcher les erreurs de modélisation. Les besoins en infrastructures sont très élevés et chers, les modifications sont compliquées dans la plupart des grands modèles relationnels, et les mises en œuvres restent couteuses. On reste sévèrement dépendant de l’informatique.
Ces dernières années, la technologie en mémoire a gagné en notoriété ; d’une part parce que de grands développeurs de logiciels en ont fait leur devise, et d’autre part parce que la mémoire physique (RAM) a connu une forte baisse des prix. Les grands développeurs de logiciels tout comme les entreprises d’autres secteurs se battent désormais pour l’intégration de ces solutions en mémoire. Il surgit donc toujours plus de solutions côte à côte (side by side ; par exemple une solution HANA non pas en dessous, mais à côté d’un SAP BW), de telle façon que, loin de se réduire, le cout total de possession augmente constamment (à supposer que les limites du bilan sont bien définies).
Nous ne pouvons et ne voulons pas jeter toute l’expérience du monde en matière de Business Intelligence, mais notre approche nous permet de la renouveler par l’emploi de nouvelles technologies montante. Nous allons vous proposer ici une combinaison de directives architecturales et d’utilisation de nouvelles technologies. Tout d’abord, nous simplifions massivement l’intégration des données et leur conservation dans les couches de données brutes. Nous voulons ensuite offrir un entrepôt de données avec des solutions simples, agiles et spécialisées. Dans un projet de Business Intelligence, nous réduirons ainsi les activités d’intégration et de modélisation des données de 80% à 40%.
De plus, une partie de la modélisation de données doit se dérouler à même l’entreprise, ce qui permet de diminuer encore drastiquement les couts. Il y a beaucoup de promesses que le cout total de possession ne tient pas vraiment. Vous comprendrez après la lecture de notre blogue de quelle façon nous pouvons massivement réduire le ce cout par une solution d’entrepôt de données, afin que la mise en œuvre devienne supportable pour une PME. Nous voulons ensuite proposer une intégration de bonne qualité pour différents cas d’utilisation. Cette expectative simple n’est malheureusement pas vraiment remplie par les nombreux producteurs et consultants en matière de BI. Par exemple, la partie planification est généralement prise en charge par des outils séparés. Planification, tableau de bord, rapport, analyse dans un outil intégré, quel que soit l’appareil, en un seul bloc. Intéressé ? Suivez notre blogue.
- Un outil de BI monobloc : nous présentons nos nouveaux partenaires technologiques.
- Modélisation de données pour les PME
- Planification et budgétisation rapides et simples pour les PME
- Une mer de données pour les PME. Comment utilisons-nous les technologies BIG DATA pour les petites quantités de données ?
- Connexions faciles aux sources !
- Comment les exigences en matière de BI peuvent-elles être simplement formulées ?
[1] Inmon, W.H. Building the Data Warehouse (Third Edition), New York: John Wiley & Sons, (2002).
[2] Kimball, R. and M. Ross. The Data Warehouse Toolkit: The Complete Guide to Dimensional Modeling (Second Edition), New York: John Wiley & Sons, 2000.
[3] Thomas Zeh: Data Warehousing als Organisationskonzept des Datenmanagements. Eine kritische Betrachtung der Data-Warehouse-Definition von Inmon. In: Informatik – Forschung und Entwicklung. 18, Nr. 1, 2003.
- TensorFlow - mai 29, 2017
- Moteur rotatif – exemple de détection d’anomalies - avril 4, 2017
- Les 3 scénarios de détection d’anomalies - mars 15, 2017