On 19.11.2019 we presented our project experience with the Predictive Maintenance Expert Group of the Swiss Alliance for Data Intensive Services. We would like to share some of these experiences in this blog.
When we discuss predictive maintenance with our industrial customers, the main topic is often the inadequate data situation. “Our machines are so good and produce hardly any errors”. Our customers are then prematurely of the opinion that predictive maintenance cannot be implemented within the time and effort involved. In this blog we want to explain how we deal with this topic.
Let’s take our Predictive Maintenance project in the distribution centres of Swiss Post as an example. In the various distribution centres, 8 sorter systems with approximately 700 wagons each are in continuous operation. Each of these wagons can have various defects, which of course happen very rarely. The next picture shows the possible defects:
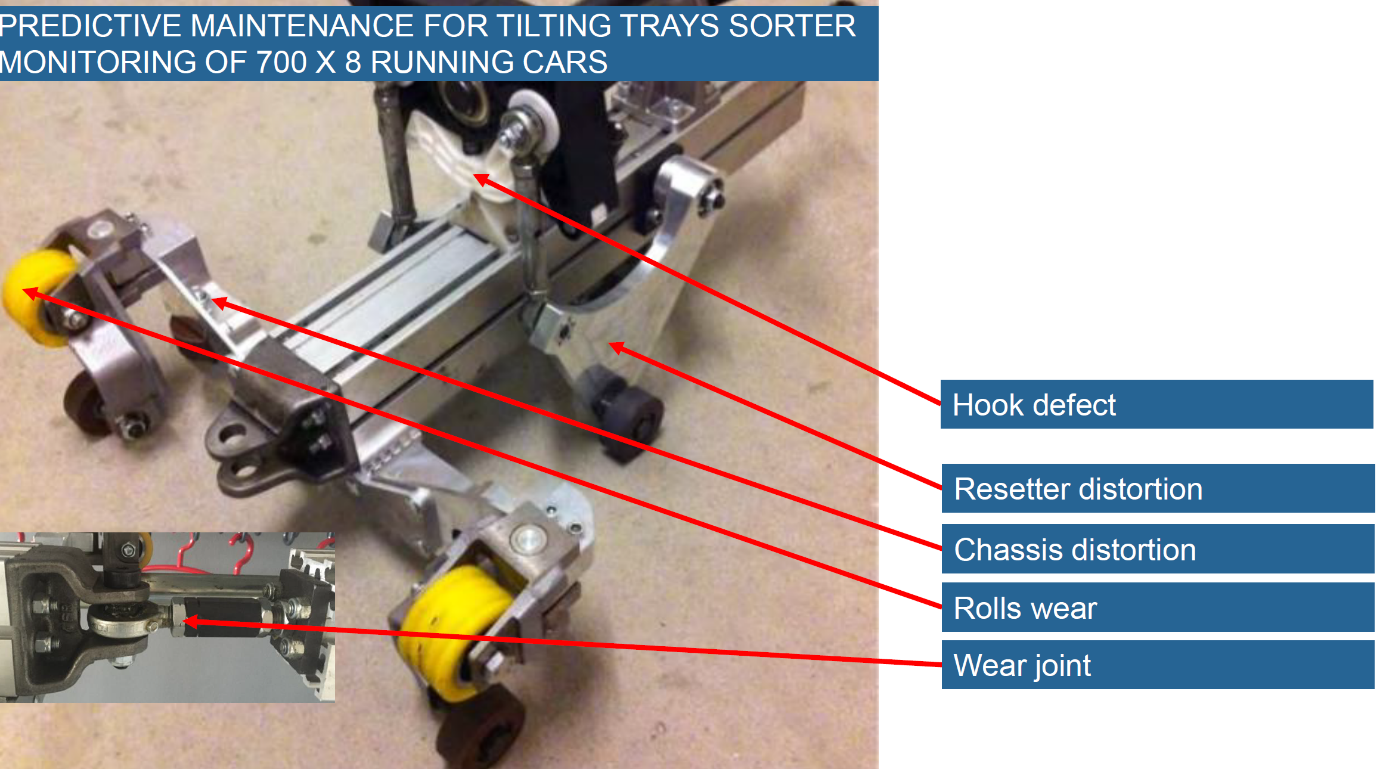
Fig. 1: Maintenance topics on the chassis of a tilting tray trolley
The important conclusion to be drawn from this project is that machine learning can achieve great results, even when very few defective cases are available for training. To explain how we do it, here are some basics:
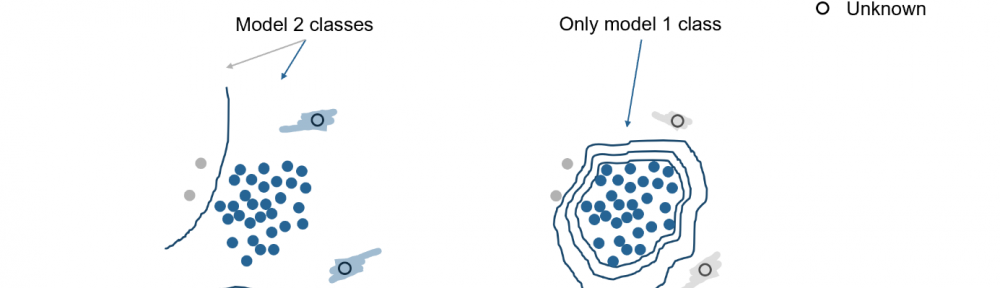
In the following figure you can see the principle of classification, which belongs to the field of Supervised Learning. In these 3 pictures we can see that a sufficient classification is not possible if the data situation is insufficient. New measurements (marked “unknown” in the picture) will be classified as “normal wagon” in the picture on the far right, even if a defect has occurred in the wagon. The classification model gives incorrect results if the training basis is insufficient. This is when the problematic cases seen in the training are not representative of all the possible problematic cases we want to identify later. In such cases the solution becomes unusable.
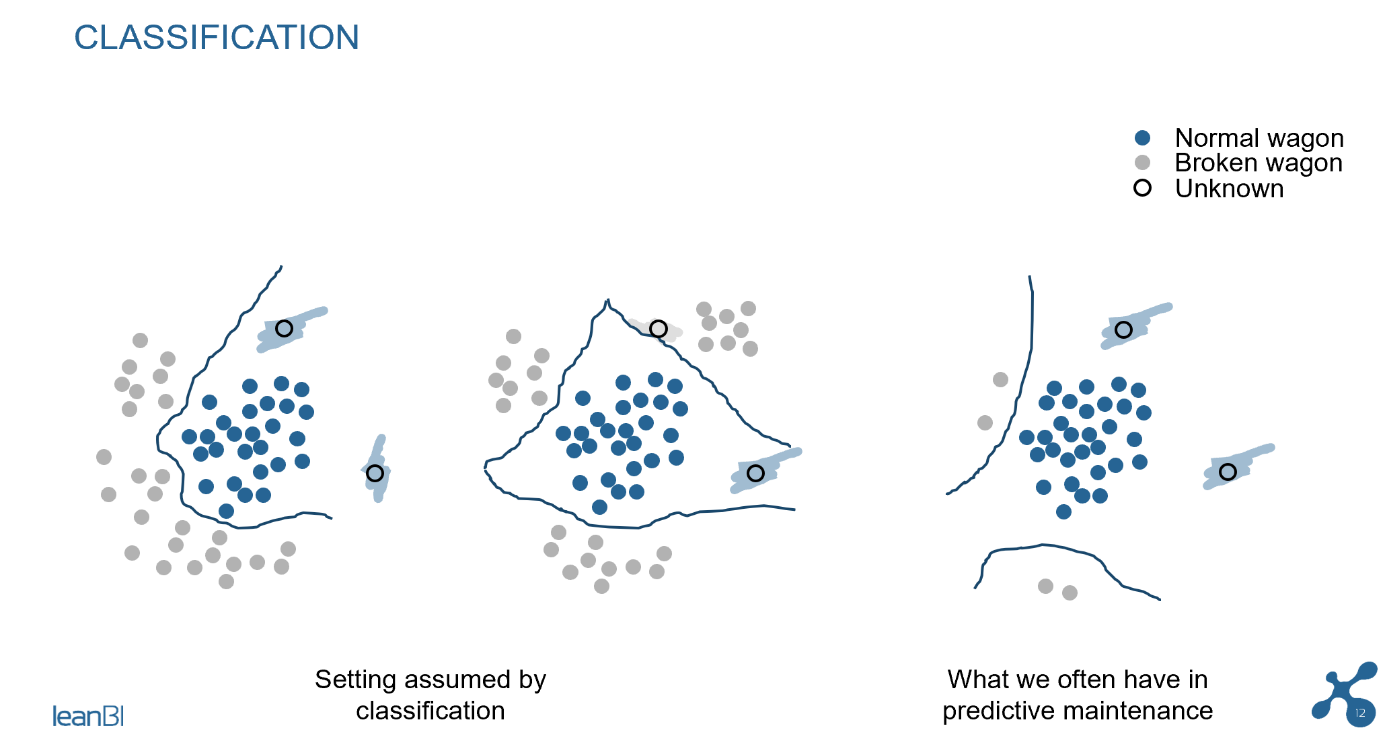
Fig. 2: Incorrect classification, if the model has only a few cases of damage for training
The situation is different with anomaly detection, an ML modelling technique that assumes hardly any problematic cases during training, and is thus considered Unsupervised. During the training phase of anomaly detection, we essentially model what is the “normal” behavior or wagons, and we only need very few examples of defects (if available), to tune the model parameters. The model can then very well detect a new defect in the field, because it only has to detect the deviation from the normal state, which is correspondingly easier for the model. See the second picture in the next diagram.
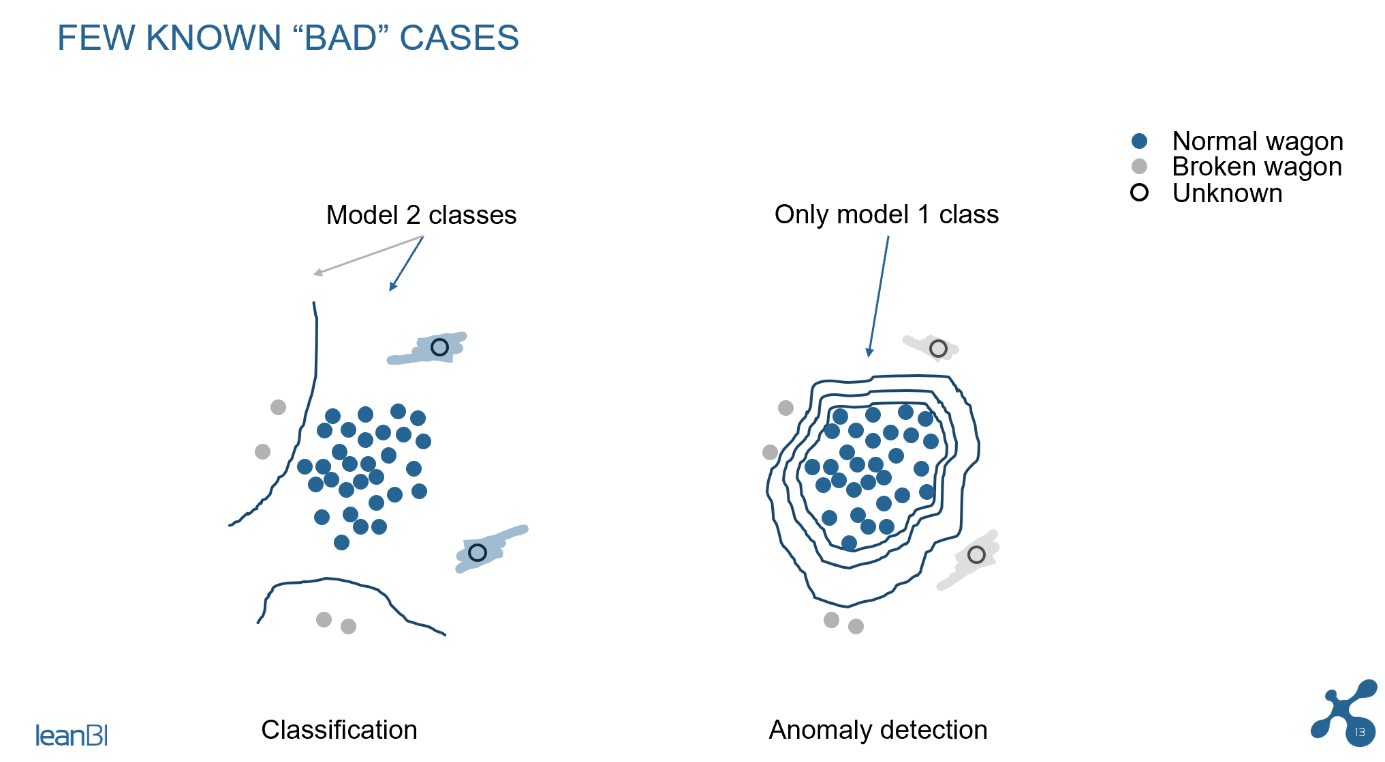
Fig. 3 Difference of classification and anomaly detection
But an anomaly detection model can do much more, as we see in the Swiss Post case. We use a stationary laser triangulation to measure bending on different parts of the chassis. We measure various points and surfaces of the car in the submillimeter range as it passes the measuring device. The evaluation of these measurements takes place within a few seconds, so that we can play the measurements on each car online in our LeanBI Cloud during operation. This makes it possible to detect changes over time and thus make more than just status statements. So you can see at an early stage whether a problem could occur in the future, and this information is then passed on to the maintenance personnel. This is predictive maintenance.
The conventional opinion that anomaly detection only detects one anomaly, but not the individual problem, is not always correct. Using the appropriate feature extraction, i.e. the selection of the survey points, we can pass on precise information about the anomaly. For example, the chassis coordinate x,y,z has shifted in the direction y by 0.4 mm. In this case this is already a very accurate localization of the problem.
But there must still be a catch then? Yes, it is true that the models are not yet very accurate on the basis of a few damage patterns. But these are so accurate that we get all possible damages within the 10% wagons that our model will indicate, so no damage slips through accidentally. It can happen that a damage is reported in error, where there is no damage at all (a “false positive”). But: The maintenance staff is 10 times faster than before, because they only have to inspect 10% of the cars. And we detect faults faster (online) and better than the maintenance staff. For example, the test measurements revealed damage to a number of wagons that were overlooked during periodic maintenance.
With this predictive maintenance solution, we prevent unplanned downtime, which is the main benefit of such a system. This is so that the customers of the Post want their parcels to arrive on time for Christmas. Unplanned downtimes can also be very expensive if a car is severely damaged. At the same time, we reduce the work of the maintenance staff and draw their attention to the specific problematic wagons. This also helps with less trained personnel.
Summa Summarum, the business case for Swiss Post is worth it.
In the area of predictive maintenance, there are problem areas that are much more complex than this case study. Can anomaly detection then fail? In such cases, at least the anomaly detection alone is not sufficient. The aim is to continuously include the know-how of the specialists in the system even more strongly in more complex subject areas. The model thus becomes “self-learning”. We are working on this topic in other projects and will report on it in the next blogs.