Modellierung von Ursachen und Wirkungen
Präskriptive Analytik ist nicht nur die höchste Stufe des analytischen Reifegradmodells, es ist auch ein Mittel, um die prädiktive Analytik robuster und genauer zu machen.
Im Bereich der Business Intelligence ist das „Analytics Reifegrad-Modell“ von Gartner allgemein bekannt. Wir bilden dieses in etwas erweiterter Form in Diag. 1 ab.

Diag.. 1: Das Reifegradmodell der Datenanalytik nach LeanBI auf der Grundlage vom Analytics Reifegradmodell nach Gartner.
Entlang der Stufen nimmt die Komplexität der Datenanalytik von unten nach oben zu. Der ursprüngliche Bereich von Business Intelligence deckt das Reporting und die Datenanalyse ab (bei der LeanBI mit OLAP, Online Analytical Processing, unter Verwendung von mehrdimensionalen Würfeln). Der obere Bereich Data Science lässt sich in prädiktiver und präskriptiver Analytik unterteilen. Die meisten heutigen Data Science Use Cases beschäftigen sich mit der prädiktiven Analytik und lassen die präskriptive Analytik aussen vor. So lassen sich mit den meisten heutigen Modellen wie Deep Learning Muster erkennen, um damit bspw. einen Schadensfall einer Maschinenkomponente vorhersagen, wie dies auch LeanBI mit LeanPredict ausführt. Mit Predictive Analytics lässt sich aber weniger gut auf die Ursachen der Schäden schliessen, umso schwieriger je breiter die Modelle sind. Deshalb wollen wir in diesem Blog mit dem Thema der präskriptiven Analytik beschäftigen, insbesondere der Modellierung von Ursachen (Causal Modelling).
Quantifizierung der Wirkung eines Faktors
Wollen wir ein Produkt optimieren, müssen wir dieses besser verstehen. Eine Produktoptimierung kann je nach Kontext mit verschiedenen Techniken angegangen werden. Im Marketing wollen wir zum Beispiel Fragen beantworten wie «Verändert die Position der Schaltfläche die Klickrate des Benutzers?». In diesem Zusammenhang haben wir die Freiheit, die Parameter (die Position der Schaltfläche) zu ändern und A/B-Tests zu verwenden, um die tatsächliche Auswirkung der Änderung zwischen Benutzern zu messen. So haben wir die Möglichkeit mit direkten Tests das Produkt zu optimieren und damit auch das Verhalten der Anwender besser zu verstehen.
Bei der vorausschauenden Wartung wollen wir Fragen beantworten wie «Führt die Änderung der Rotationsgeschwindigkeit, die ich im letzten Monat beobachtet habe, zu einem früheren Bruch der Maschine?» Wenn wir in diesem Fall davon ausgehen, dass die Drehzahländerung ohne unser Zutun erfolgte (wie eine Anomalie) und wir sie nicht direkt kontrollieren, können wir ihre Wirkung nur aufgrund von Beobachtungen messen. Wir könnten die Maschinen analysieren, die kaputt gegangen sind und solche die weiterhin laufen, um daraus zu schliessen, ob die unerwartete Änderung der Rotationsgeschwindigkeit zum Defekt führt. Nur haben wir dafür normalerweise keine Möglichkeit einer genügenden Datenerhebung. Bei dieser Art von Problemen, bei denen wir keine Kontrolle über die betrachteten Parameter haben, sondern die Ergebnisse nur a posteriori beobachten können, helfen uns die mathematischen Modelle der kausalen Inferenz weiter.
Kausale Inferenz und Kausalität versus Korrelation
Im Bereich vom Causal Modelling gibt es verschiedene Ansätze. Einer der wichtigsten Vertreter auf dem Gebiet des Causal Modelling ist Judea Pearl, der mit vielen Preisen geehrt wurde, unter anderem auch 2011 mit dem bekannten Turing Award. Er ist der Pionier der Bayesschen Netze, kausalen Modelle über die wir heute schreiben wollen.
Prädiktive Analytik hat seine Tücken, wenn wir beeinflussende Faktoren in den Modellen zu wenig berücksichtigen. Wir bringen dafür ein medizinisches Beispiel von Judea Pearl, weil dieses für uns alle sehr einleuchtend ist: Wenn wir den Einfluss von sportlichen Aktivitäten auf den Cholesteringspiegel auftragen, erhalten wir eine Abhängigkeit nach Diag. 2.
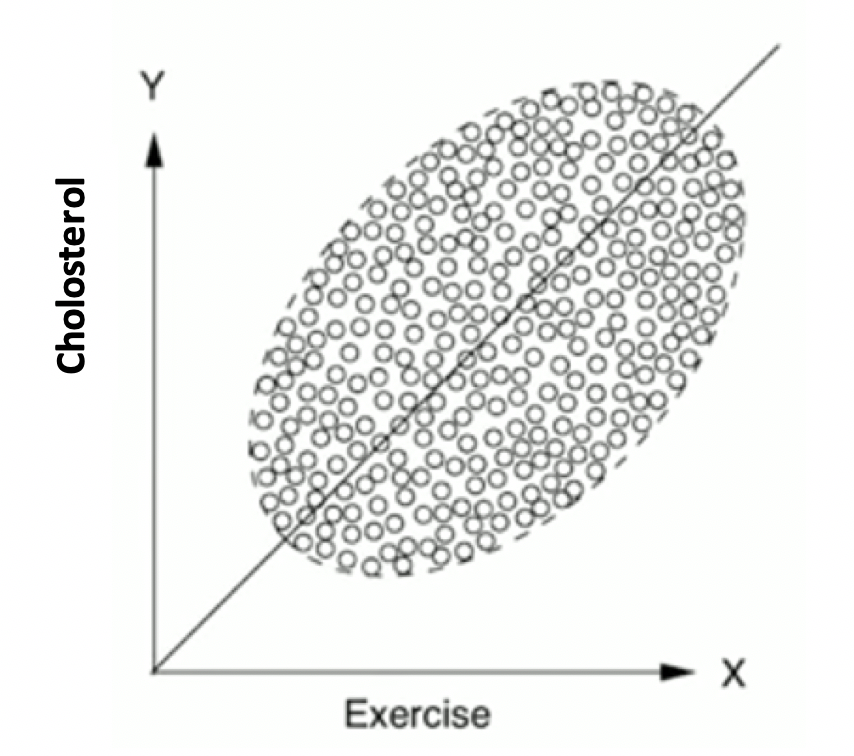
Diag. 2: Abhängigkeit der Cholesterin-Spiegels von sportlichen Aktivitäten nach [1]
Wir interpretieren, dass mehr Sport zu höheren Cholesterinwerten führt, weil wir eine hohe Korrelation zwischen den beiden Variablen sehen. Eigentlich erwarten wir das nicht. Was stimmt also nicht? – Wir haben einen wichtigen Faktor übersehen, nämlich das Alter. Wenn wir diesen Parameter zusätzlich berücksichtigen, interpretieren wir plötzlich die gleiche Anzahl von Punkten ganz anders, nämlich korrekt, indem wir die Menschen nach Altersgruppen gruppieren, bevor wir jede Gruppe einzeln analysieren. Wie erwartet, gibt es nun für jede Gruppe eine negative Korrelation zwischen Cholesterin und Sportmenge. Warum war dies vorher nicht offensichtlich? Weil bei diesen Daten ältere Menschen nicht nur einen höheren Cholesterinspiegel haben, sondern diesen auch durch mehr Bewegung bekämpfen. Mit zunehmendem Alter nehmen beide Parameter zu, so dass sie hoch korreliert erscheinen, wenn wir das Alter nicht berücksichtigen. Wenn wir jedoch das Alter „kontrollieren“, verstehen wir, dass es die Ursache für mehr Bewegung und gleichzeitig für einen höheren Cholesterinspiegel ist. Der Cholesterinspiegel steigt mit dem Alter, und Sport senkt ihn für jede Altersgruppe (siehe Diag. 3).
![Einbezug des Alterseinflusses auf den Cholesterinspiegel nach [1]](https://leanbi.ch/wp-content/uploads/2020/04/Screen-Shot-2020-04-30-at-16.18.50.png)
Diag. 3: Einbezug des Alterseinflusses auf den Cholesterinspiegel nach [1]
Falsche Interpretationen wie Diag. 2 können im Data Science passieren, indem falsche Parameter in die Modelle einfliessen oder weil die Wichtigkeit der Parameter falsch erkannt werden. Das kann dann mehr oder weniger schlimme Folgen haben. Mindestens gehen solche Fehlinterpretationen aus ungenügenden Modellen mit einem Vertrauensverlust in die Data Science Fähigkeiten einher.
Deshalb ist eine wichtige Erkenntnis, dass die Forschung der Ursachen und Zusammenhänge unterstützend wirkt, aussagekräftiger und besser zu modellieren. Mit der Ursachenforschung werden die Korrelationen analytischer Modelle zu Kausalitäten.
Kausale Schlussfolgerung in der Industrie
Wie machen wir das nun konkret in unserem Fachgebiet der industriellen Datenanalytik? In der industriellen Datenanalytik erkennen wir einen herannahenden Schaden durch eine Abweichung der Messdaten von der Normalität. Wir nennen diese Messdaten „Effekte“. Nehmen wir zum Beispiel Temperatur als Messgrösse. Nimmt eine Temperatur am Ort einer Oberfläche zu, lässt sich vielleicht einen kommenden Schaden vorhersagen. Aber wie sicher können wir sein?
Schauen wir uns dazu den folgenden generischen Graphen an:
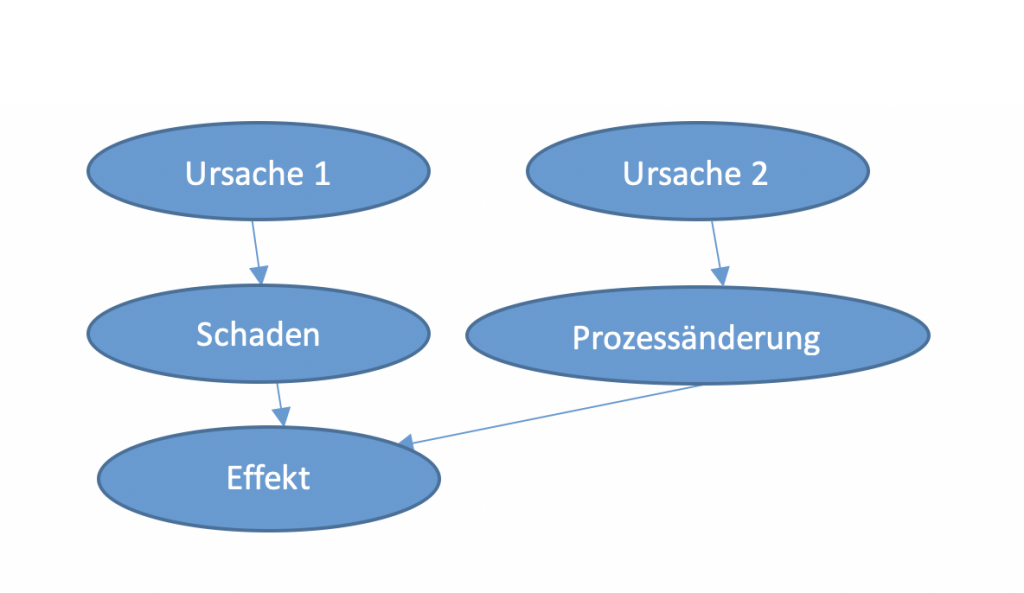
Diag. 4: Ursachen – Wirkungs- Graph eines Maschinenschadens
Ein gemessener Effekt kann mehrere Gründe haben und jeder Grund hat wiederum ein oder mehrere Ursachen. Haben wir uns aber nicht genügend mit den Ursachen und Zusammenhängen der Effekte beschäftigt, besteht die Gefahr, dass wir Fehlalarme produzieren. Denn eine Temperaturzunahme kann mehrere Gründe haben, zum Beispiel eine Prozessänderung oder ein Schaden an einer Komponente. Wir müssen also die Kausalitäten herausfinden, dafür braucht es Spezialisten aus den entsprechenden Fachgebieten. Für die LeanBI bedeutet dies, Workshops mit den Spezialisten vor Ort durchzuführen, sei es mit den Ingenieuren oder Betriebsleuten der Produktionen.
Wenn wir also die Ursachen-Wirkungsketten besser verstehen, können wir Wahrscheinlichkeiten definieren, unter welchen Bedingungen sich welche Effekte ergeben. Wie ist dabei die Vorgehensweise? Wir bilden kausale Netze, sogenannte Graphen. Ein wichtiger Vertreter kausaler Modelle sind die „Bayesian Network“. Diag. 5 zeigt ein einleuchtendes Beispiel aus der Medizin. Wir bilden für jede Wirkung Wahrscheinlichkeiten und schreiben diese in Tabellen.
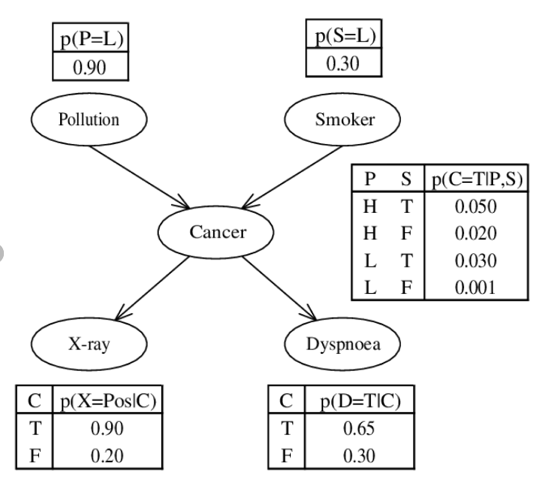
Diag. 5: Beispiel eines einfachen „Bayesian Network“ Graphen: Zusammenhang von Lungenkrebs nach [2]
Nehmen wir zum Beispiel die Tabelle in der Mitte: Wenn wir P (Pollution) = H (High) und S (Smoker) = T (True) haben, ist die Wahrscheinlichkeit Krebs zu bekommen 0.05, als Nichtraucher S (Smoker) = F (False) bei gleicher Umgebung nur 0.02. Die Resultate verschiedener Effekte/Messmethoden wie X-Ray oder Dyspnoe (Atemschwerheit) lassen mit gewissen Wahrscheinlichkeiten auf Krebs schliessen. Es gilt also die Wahrscheinlichkeiten mit Studien, Experimenten oder mit Hilfe der Know How Träger zu ermitteln.
Es kann sehr komplex sein, richtige Ursachen- Wirkungsmechanismen zu evaluieren. Und die Interpretation ist schwierig. Ereignisse müssen zum Beispiel nicht gleichzeitig vorkommen und können sich auch über die Zeit verändern. Deshalb ist ein zentraler Punkt, die richtigen Fragen zum Netzwerk zu stellen (Judea Pearl nenn dies „Do Operator“). Fragen sind dabei auch Konterfragen: Was ändert sich, wenn Ereignis B nicht eintritt? Genannt werden diese „Counterfactuals“. „Was ist, wenn es nicht Krebs ist, was das Röntgenbild zeigt?“ Mit solchen Fragen reichern wir das Netzwerk an und verbessern es.
Das spannende ist, dass sich die Graphen 1:1 in mathematische Modelle überführen lassen. Ein wichtiger Begriff dazu ist die konditionale Wahrscheinlichkeit, „Conditional Probability“. Wir ermitteln die Wahrscheinlichkeit eines Ereignis A unter der Bedingung, dass Ereignis B zutrifft. Geschrieben wird dies P(A I B) oder PB (A). Im Bayesian Netzwerk werden so die Knotenpunkte beschrieben. Und damit lässt sich das mathematische Modell des ganzen Graphen aufbauen.
Die Bayesian Network Modelle bilden mathematisch eine durch uns erkannte Ursachen- Wirkungs-Realität ab. Es ist eine reduzierte Realität auf Einflüsse und Bereiche, die uns interessieren, und auch immer mit Unsicherheiten verbunden. Innerhalb solcher Netze können wir die Realität explorieren, indem wir die mathematischen Modelle anwenden und variieren. Wir erweitern damit modelltechnisch unseren Wissensraum. Das ist ein grosser Vorteil, denn wir können kaum mit Menschen experimentieren, um die Ursachen des Krebses besser zu verstehen. Im industriellen Umfeld genau gleich. Die Datenlage ist beschränkt und Testdaten sind teuer oder gar nicht erhältlich. Die Modelle helfen uns, die Maschinen und deren Schäden besser zu verstehen.
Haben nicht bereits «Expertensysteme» das Problem gelöst?
Auch bei der Umsetzung von klassischen Expertensystemen braucht es auch Experten aus den jeweiligen Bereichen. Was machen Expertensysteme anders als die gerade betrachtete kausale Modellierung? Es gibt einen grundlegenden Unterschied zwischen den beiden Ansätzen. In Expertensystemen ist das Know-how der Feldexperten in der „Inferenzmaschine“ fest kodiert, in Form von logischen Regeln, nicht als Wahrscheinlichkeitsverteilungen. Die Experten kodierten klar verstandene Ausfallmechanismen, was natürlich sehr restriktiv und in der Praxis häufig nicht funktioniert hat, da die unterschiedlichen Umwelteinflüsse zu wenig berücksichtigt werden.
Bei der kausalen Inferenz hingegen geben die Experten eine Reihe von möglichen Mechanismen an, die zu einem Versagen führen könnten, um einen oder mehrere Kausalgraphen zu erstellen. Dann liegt es an den Daten, zu erklären/zu quantifizieren, welcher der Fälle plausibler sind, während die Experten in einer nächsten Iteration die darauf basierenden Modelle verfeinern können. Sind die Modelle einmal festgelegt, können wir mit ihnen nicht nur diagnostische Analysen durchführen, sondern auch prädiktive und präskriptive.
Ein Blick in die Zukunft
Die Suche nach der Ursache eines Ausfalls („warum ist es passiert“) fällt per se meist in die Kategorie der diagnostischen Analytik. Sobald wir jedoch ein Kausalmodell haben, das zu unseren Daten passt, können wir es als eine weiche Form des digitalen Zwillings des Prozesses verwenden. Das Modell ist ein leistungsfähiges Werkzeug, das wir für die prädiktive, aber auch für die präskriptive Analyse verwenden können.
Das moderne maschinelle Lernen, dessen Flaggschiff das Deep Learning ist, hat viele Probleme in Angriff genommen, die vor 10 Jahren noch unvorstellbar waren. Der heutige Bedarf besteht jedoch mehr und mehr darin, interpretierbare oder erklärbare Modelle zu haben, und tiefes Lernen allein reicht nicht aus. Probabilistisches maschinelles Lernen und Modellierung können diese Lücke füllen, denn es zeichnet sich bereits ein neuer Trend ab, bei dem Deep Learning mit probabilistischer Modellierung kombiniert wird. Es ist kein Zufall, dass die heute meistgenutzte Bibliothek für Deep Learning, Tensorflow, erst kürzlich ein „Wahrscheinlichkeits“-Modul mit sehr wichtigen Inferenz-Tools hinzugefügt hat. Die Möglichkeiten sind endlos.
In Zukunft wird die LeanBI vermehrt mit diesen neuen Methoden arbeiten So kann das Resultat eines Bayesian Network der Input für Deep Learning sein. Ein Knotenpunkt eines Bayesian Network kann ein Deep Learning Modell sein. Oder die Prognose eine Deep Learning Modells fliesst in ein Bayesian Network ein, um die Ursache eines Problem besser zu erkennen.
Präskriptive Analytik ist nicht nur die höchste Stufe des analytischen Reifegradmodells, es ist auch ein Mittel, um die prädiktive Analytik robuster und genauer zu machen.
Literatur:
[1] Keynote: Judea Pearl – The New Science of Cause and Effect, PyData LA 2018: https://www.youtube.com/watch?v=ZaPV1OSEpHw&t=3299s

- Blog: Braucht Industrie 4.0 ein Data Warehouse oder ein Lakehouse? (Teil 2) - Januar 17, 2024
- Blog: Braucht Industrie 4.0 ein Data Warehouse oder ein Lakehouse? (Teil 1) - Januar 17, 2024
- Zusammenschluss Substring und LeanBI - Dezember 31, 2023