IoT und Predictive Analytics: Fog und Edge Computing für Industrien versus Cloud (19.1.2018)
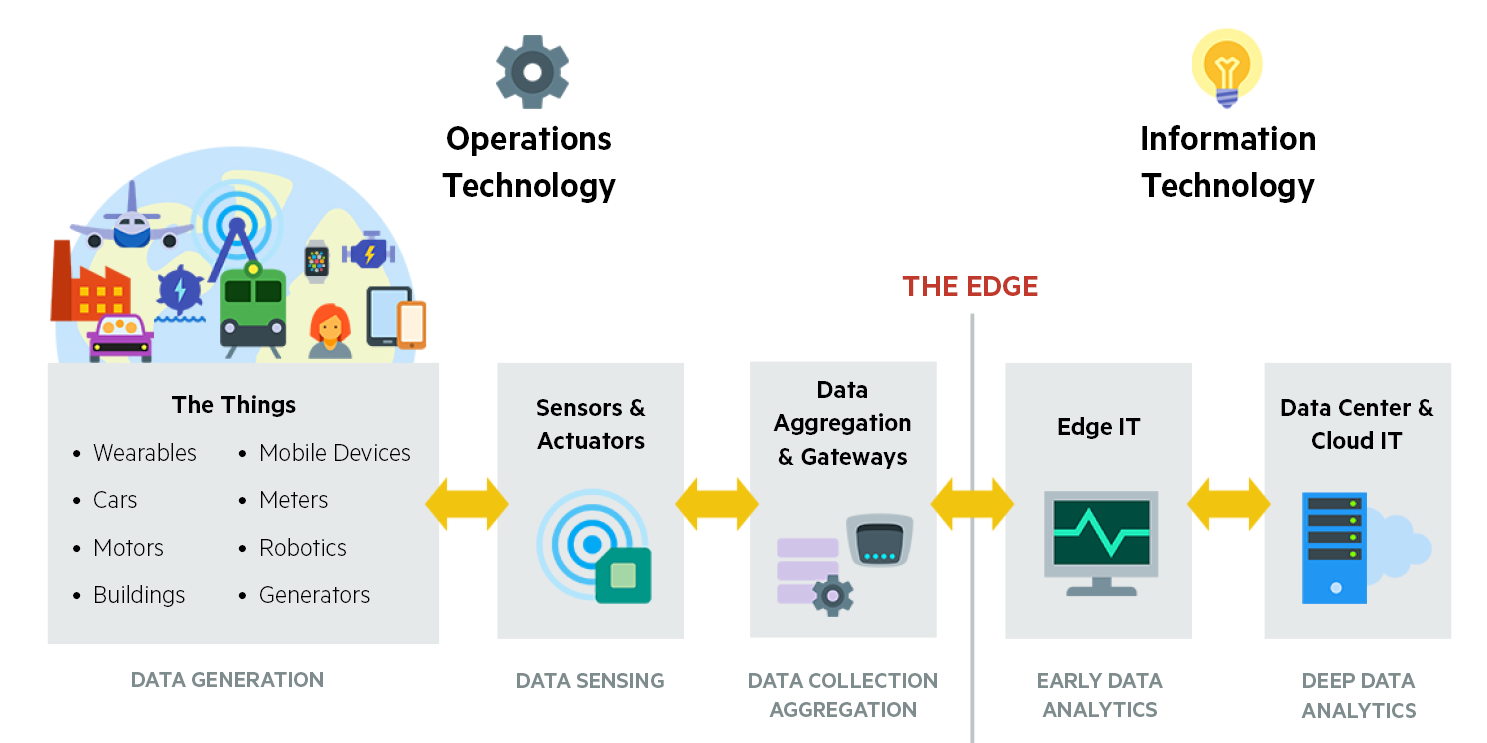
Bild: ESG Research 2016
Warum nicht immer Cloud?
Von unseren industriellen Kunden wird immer wieder angezweifelt, ob die Cloud der richtige Weg sei, um IoT und Predictive Analytics in Industrieprozessen, Produktionsanlagen und Maschinenparks zu implementieren. Einige Gründe sprechen dafür, einige aber auch dagegen:
IoT und Predictive Analytics in der Cloud: Was spricht dafür?
- Aus der Cloud können Prozesse zentral überwacht werden. Mit den Daten lassen sich die Prozesse optimieren und besser betreiben. Die Informationen aus den Prozessen können zudem in die Produktentwicklung einfliessen.
- In der Cloud sind die Daten zentral in einer Datenbank abgelegt und können für zukünftige aktuell noch unbekannte Analysen umfassend eingesetzt werden (Data Pool, Single Source of Truth).
- Komplexe Algorithmen mit grossen Datenmengen können auf schweren Big Data Infrastrukturen ausgeführt werden (z.B. auf Hadoop oder MPP-Massive Parallel Processing Infrastrukturen). Es bestehen keine Limiten bezüglich CPU und RAM.
- Die Daten können über eine zentrale Einheit zwischen den „Things“ ausgetauscht werden. Das bringt strukturierten Informationsaustausch mit sich (im Gegensatz zur sog. Spagetti-Vernetzung).
- Das Thema Datensicherheit kann zentral angegangen werden und muss nicht dezentral für jede Einheit separat gelöst werden.
IoT und Predictive Analytics in der Cloud: Was spricht dagegen?
- Die Daten verlassen das Netzwerk des Industrieprozesses (zum Beispiel des Herstellprozesses), was nicht von allen Kunden akzeptiert wird. Es besteht das potentielle Risiko, dass Prozess Know-How abgesaugt wird.
- Über die Cloud kann ein Angriff auf die Daten der Firma oder sogar auf die Anlagen selbst erfolgen (Cyber Security). Ein zentrales Element wie z.B. die IoT Plattform eines grossen Providers ist grösser und bekannter; somit ist das Interesse und die Gefahr, dass ein solcher Punkt angegriffen und gehackt wird, viel grösser.
- Die Latenzzeit zwischen Maschine und Cloud beeinträchtigt den Eingriff im Millisekunden-Bereich (Real Time oder Near Real Time Applikationen). Viele Use Cases im Machine Learning und im datenanalytischen Bereich können so nicht oder nur eingeschränkt funktionieren.
- Die Bandbreite des Netzwerkes ist oft nicht ausreichend, um die grossen Datenmengen zu übertragen.
- Das Netzwerk kann ausfallen, die Verfügbarkeit der Applikation ist dann nicht sichergestellt. Im schlimmsten Fall kann sich das auf die Anlagenverfügbarkeit auswirken.
- Bei grossen Datenmengen kann eine Cloud wie z.B. MS Azure IoT, Predix, Mindsphere, Amazon AWS, Google Cloud, usw. sehr teuer werden, da die Lizenzmodelle mengenspezifisch aufgesetzt sind.
Was ist Edge und wann wird es verwendet?
Ziel neuer Konzepte ist es, die Geräte und Sensoren in der Edge (im Deutschen am besten mit Rand übersetzt, in unserem Fall mit Industrieanlagen) oder in der Fog (d.h. im Industrienetzwerk) intelligenter zu machen, so dass die Kommunikation nicht nur von und zu der Cloud, sondern – wo sinnvoll – wieder zwischen den Geräten selbst stattfindet.
Warum also nicht Applikationen wie Predictive Maintenance direkt auf der Maschine ausführen? Dabei lassen sich Micro-Controllers einsetzten, die aber bezüglich Speicher und RAM beschränkt sind. Solche kleinen Prozessoreinheiten kommen dann auf Raspberry Pi’s, Onion Omega 3 oder ähnlichen Fabrikaten zum Einsatz, die kleine und kostengünstige IoT Umgebungen zur Verfügung stellen. Diese Einheiten weisen wichtige Schnittstellen wie WiFi, Bluetooth und USB auf, die Leistungen sind aber rechtgering, ein Raspberry Pi Zero W verfügt über z.B. 1 GHz CPU und 512 MB Storage bei einem Preis von 10$ pro Einheit.

Bild 1: Micro Controllers und Raspberry Pi‘s
Damit auf diesen Systemen Algorithmen laufen können, müssen die Algorithmen sehr «leicht» gemacht sein, was häufig nicht möglich ist.
Was ist also die nächst grössere Einheit an Compute Technologie? Heute lassen sich auch sogenannte SoC (System on a Chip) Bauelemente einsetzen. Diese besitzen sehr viel höhere Leistungsdichten bei gleichzeitig geringem Platzbedarf. Diese sind bezüglich Hardwarekosten recht günstig, müssen aber speziell für den Einsatz entwickelt werden, was dann wiederum mit Entwicklungskosten verbunden ist.

Bild 2: Beispiel einer SoC Technologie
Einsatz finden solche Systeme angefangen bei mobilen Telefongeräten bis hin zu Recheneinheiten in Cloud Centern. Die Leistungen gehen entsprechend bis 54 Cores hoch, 3 GHz, 512 GB RAM, 1 TB Storage und 100 Gbps Bandbreite, sind aber mit einigen 100 $ auch einiges teurer als die Micro Controllers und Raspberry Pi‘s.
Warum braucht es Fog Computing?
Natürlich könnten wir auch einen Server an eine Maschine stellen, welcher bis zu 176 Cores, 2 TB RAM und 460 TB Storage ausweist. Die Hardware Kosten würden dann aber dramatisch zunehmen und wir müssten uns die Frage stellen, wie teuer eine maschinennahe analytische Einheit sein darf. Dies ist natürlich abhängig von dem Preis der Maschine selber, aber in vielen Fällen lohnt sich dies vermutlich nicht.
Fog arbeitet mit der Cloud, während der Edge durch den Ausschluss der Cloud definiert wird. Fog arbeitet hierarchisch, wogegen Edge auf eine kleine Anzahl von Schichten beschränkt ist. Fog befasst sich neben der Berechnung auch mit Vernetzung, Speicherung, Steuerung und Beschleunigung. Mit Fog Computing kann daher eine interessante und preisgünstige Zwischenlösung zur Cloud geschaffen werden. Mit Fog wird die Rechenleistung an die Peripherie der Netzwerke gedrückt und damit für eine Gruppe von „Dingen“ zwischen Edge und Cloud ausgeführt.
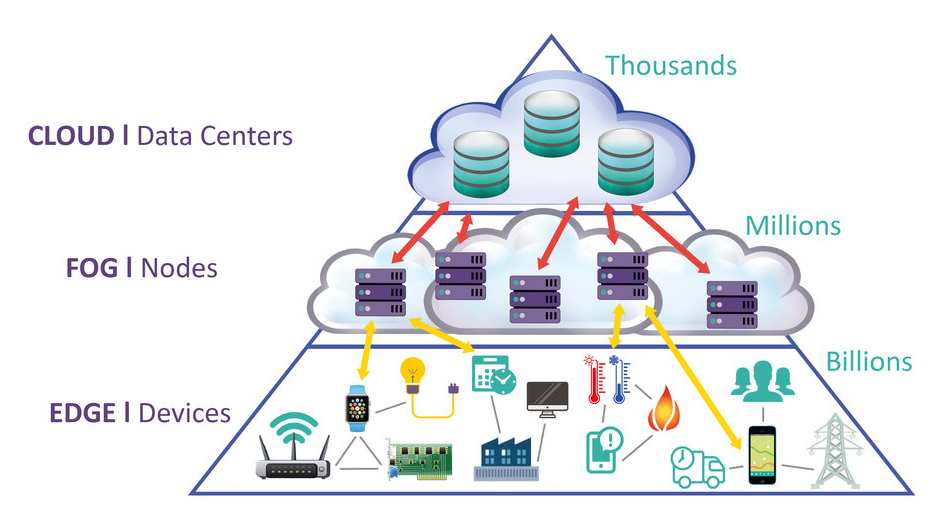
Bild 3: Darstellung der Fog Architektur
Fog: Ein Architekturkonzept
Fog ist zuerst einmal ein Architekturansatz, zweitens eine Software und Drittens eine Hardwarekomponente. Der Ansatz ist noch recht neu, stammt aus den Jahren 2014, im 2015 wurde von einigen wichtigen Exponenten wie Cisco, Intel, Dell, Microsoft und Princeton University das Open Fog Konsortium gegründet. Im Februar 2017 ist dann das erste Architekturkonzept publiziert worden, welches hier eingesehen werden kann:
https://www.openfogconsortium.org/wp-content/uploads/OpenFog_Reference_Architecture_2_09_17-FINAL.pdf
Die Publikation ist noch nicht sehr konkret und man muss sich durch 162 Seiten Paper kämpfen. Trotzdem lohnt sich eine Sichtung des Dokuments, und ohne hier genauer darauf einzugehen, ist für uns folgende Zusammenarbeit von Edge, Fog und Cloud essentiell.
Das Machine Learning (ML) Modell wird auf einer Data Science Plattform entwickelt. Das kann Offline oder in der Cloud geschehen. LeanBI setzt dafür als Plattform Dataiku ein. Das ML Modell wird dann auf eine produktive Plattform exportiert. Je nach den Anforderungen läuft dann das ML Modell auf der Edge, in der Fog oder direkt in der Cloud. Der Trainings-Task zur Modell-Optimierung wird in der Regel an die Cloud abgegeben, da dieser Task rechenintensiv ist und eine breite Datenbasis benötigt. Das Modell wir damit periodisch in der Cloud mit neuen Daten optimiert, um dieses verbesserte Modell dann auf die Fog oder Edge periodisch anzuwenden. Prinzipiell lässt sich dieser Trainings-Task auch offline ausführen, je nachdem, wie häufig dieser stattfinden muss.
Fog: Ein Stück Software
Die Softwarelandschaft rund um Edge und Fog Computing ist momentan noch recht übersichtlich. Dabei ist der Funktionsumfang teilweise sehr unterschiedlich. Cloud Anbieter wie MS Azure IoT, Predix, AWS oder IBM Watson haben im 2016/2017 Edge/Fog Komponenten lanciert (meistens als Open Source), um besonders als Bindeglied zwischen der Edge und der Cloud zu wirken. Dabei werden Funktionalitäten bereitgestellt, die das Machine Learning Modell auf der Edge laufen lassen. Hier drei Beispiele dafür:
AWS Greengrass: https://aws.amazon.com/de/greengrass/
Azure IoT Edge: https://azure.microsoft.com/de-de/services/iot-edge/
IBM Edge Analytics: https://console.bluemix.net/docs/services/IoT/edge_analytics.html#edge_analytics
Was Data Preparation, Data Cleansing und Data Processing auf der Edge/Fog anbelangt, sind diese Lösungen noch sehr programmieraufwändig. Die Lösungen sind nicht unabhängig von der Cloud Lösung einsetzbar. Dann gibt es jene Software Lösungen, die unabhängig vom Cloud Provider Edge und Fog Computing möglich macht. Foghorn, ein Silicon Valley Start Up Unternehmen, ist ein Beispiel dafür.
Foghorn: https://www.foghorn.io/technology/
Foghorn bietet die Möglichkeit der Datenaufbereitung und einer sehr schnellen Ausführungs- Engine, der sogenannten CEP Engine. CEP bedeutet Complex Event Processing und beinhaltet verschiedene Methoden, um Logik möglichst in Real Time abzuhandeln. CEP kann innerhalb von Docker betrieben werden und läuft damit auch direkt auf der Edge. Meistens läuft die Software nicht auf den Endpunkten der Anlagen, sondern auf den physischen Gateways.
Fog: Ein Stück Hardware
Die physischen Gateways bringen den Vorteil mit sich, dass Software immer noch Nahe der Anlage läuft, gleichzeitig aber ein ganzes Bündel an Maschinen und Anlagenpunkten bedient werden können. Netzwerkmässig läuft die Software damit noch im Automatisierungsnetzwerk, also abgekoppelt von der Cloud, der Datenaustausch findet über die Standard-Konnektoren der Gateways statt. Wichtige Daten können aber von diesem Punkt einfach der Cloud zur Verfügung gestellt werden.
Um einen Eindruck über die Leistungsfähigkeit heutiger Gateways zu erhalten, hier einige Beispiele:
Hilscher Gateway „On Premise“ https://www.hilscher.com/fileadmin/cms_upload/en-US/Resources/pdf/netIOT_Edge_DS_Datenblatt_10-2015_DE.pdf

Weist zu den Maschinen hin die wichtigen Feld- und IoT Protokolle auf: Profibus, Profinet, Modbus, MQTT, OPC-UA und andere. Leistungsmässig bis 2 GHz, 4 GB DDR3 RAM und 128 GB SSD. Physische Trennung von Automatisierungs- und Cloud Netzwerk aus Gründen der Security.
Dell Edge Gateway der 5000 Series
http://www.dell.com/ch/unternehmen/p/dell-edge-gateway-5000/pd
Als Vergleich dieses Dell Edge Gateway, welches etwas schwächere Leistungsdaten 1.33 GHz, 2 GB DDR3 RAM und 32 GB SSD in der gleichen Preisklasse von ca. 1000 $.
HP stellt sowohl Mittelklasse als auch High End Gateways her. Hier eine Mittelklasse Ausführung
HP Gateway: HPE GL20 IoT Gateway
Intel® i5 CPU, 8 GB RAM, 64 GB SDD Storage
Aber auch eine High End Ausführung wie folgendes System zu haben:

HPE Edgeline EL1000 Converged Edge System
Mit bis zu 16 Cores und 4 TB Disc Storage lassen sich hier schon sehr schöne analytische Lösungen betreiben.
Zusammenfassung und Fazit
Zukünftige analytische Lösungen werden weder nur auf der Maschine noch nur in der Cloud betrieben werden. Immer häufiger werden stattdessen Fog Architekturen die passende Lösung sein.
Hier kommen Kombinationseinsätze von physischen Gateways und Cloud Plattformen zum Einsatz, eine kostengünstige Form zur Umsetzung analytischer Lösungen nahe der Maschine oder Anlage bei gleichzeitiger optimaler Nutzung von Compute Ressourcen in der Cloud.
Welche Herausforderungen verbleiben?
- Die IoT/Edge & Fog Lösungen sind neuem Datums und zur Zeit einer starken Entwicklung unterworfen.
- Es ist immer zu definieren, welche Daten in die Cloud gegeben und welche Daten in der Edge und Fog verbleiben.
- Storage, CPU und Kostengrenzen in der Edge/Fog.
- Modellbildung an einem Ort – Ausführung und Verteilung an mehreren Orten.
- Standards für Peer to Peer Lösungen sind noch nicht genügend vorhanden.

- Blog: Braucht Industrie 4.0 ein Data Warehouse oder ein Lakehouse? (Teil 2) - Januar 17, 2024
- Blog: Braucht Industrie 4.0 ein Data Warehouse oder ein Lakehouse? (Teil 1) - Januar 17, 2024
- Zusammenschluss Substring und LeanBI - Dezember 31, 2023