Blog: Braucht Industrie 4.0 ein Data Warehouse oder ein Lakehouse? (Teil 1)

Abb.1: Warehousing im Umfeld Industrie 4.0
Bekannt ist, dass sich mit IIoT (Industrial Internet oft Things) eine Produktion in vieler Hinsicht überwachen und damit auch optimieren lässt. Durch Monitoring werden Ausfälle an den Maschinen vermieden oder sogar Ausfälle genügend früh vorhergesagt und damit ungeplante Stillstände in ein geplantes Wartungsfenster überführt. Das nennt man dann «vorausschauende Wartung» oder englisch «Predictive Maintenance». Auch lässt sich durch Energie-Monitoring herausfinden, wo die Hebel am grössten sind, um im Produktionsprozess den Energieverbrauch bzw. CO2-Ausstoss schrittweise zu vermindern. Letzteres ist in Kombination mit Rückverfolgbarkeit ein Thema, welches besonders im letzten Jahr von industriellen Unternehmen aufgenommen wurde. Solche Anwendungen von IIoT sind aber nur die eine Seite der Medaille.
Ein noch viel grösserer Hebel der Optimierung der Produktion ist die Reduktion der Stillstandszeiten durch verbesserte Produktionsführung und -planung. Nochmals einen Schritt weitergedacht erweitert sich die Shopfloor-Planung auf eine übergeordnete Planung in Verbindung mit der Intra- und Extralogistik. Das sind alles datengetriebene Prozesse, die heutzutage in unterschiedliche, granulare Planungseinheiten auseinanderdividiert werden. Mit Künstlicher Intelligenz (KI) besteht das Potential eine Gesamtplanungen von kurzfristig (Tages bis Wochenplanung) bis mittelfristig (Monats- bis Jahresplanung) summarisch auszuführen.
«Realtime» Daten und immer ausgeklügeltere Datenanalytik & Datenoptimierung ermöglichen eine Prozessoptimierung, die umso bessere Ergebnisse liefert, je besser Daten entlang des gesamten Prozesses zentral verfügbar gemacht werden. Dieses Thema beleuchten wir in diesem Artikel detaillierter.
Warum geht es nicht mit ERP und MES allein?
Mit der Ausreizung der Automation (also gegen Ende von Industrie 3.0), bestand um die Jahrtausendwende die Meinung, eine nahezu maximale Effizienz im Produktionsprozess erreicht zu haben. Retrospektiv ist dies eine Fehleinschätzung, nicht nur im Bereich der Werkstattproduktion, sondern genauso in der Linien- bzw. Massenproduktion. Mit dem Aufkommen von IIoT vor 20 Jahren wurde die prinzipielle Grundlage geschaffen, den gesamten Liefer- und Produktionsprozess online zu überwachen und damit die OEE (Overall Equipment Effektivness) nicht nur in der Produktion, sondern über den gesamten Prozess vom Lieferanten bis zum Kunden als OPE (Overall Process Effectiveness) in Richtung Echtzeit zu optimieren. Je mehr sich der Markt und die Möglichkeiten in Richtung «Chargengrösse Eins» bzw. personalisierte Produkte hinbewegen, umso wichtiger aber auch gleichzeitig komplexer wird die Optimierung der OPE.
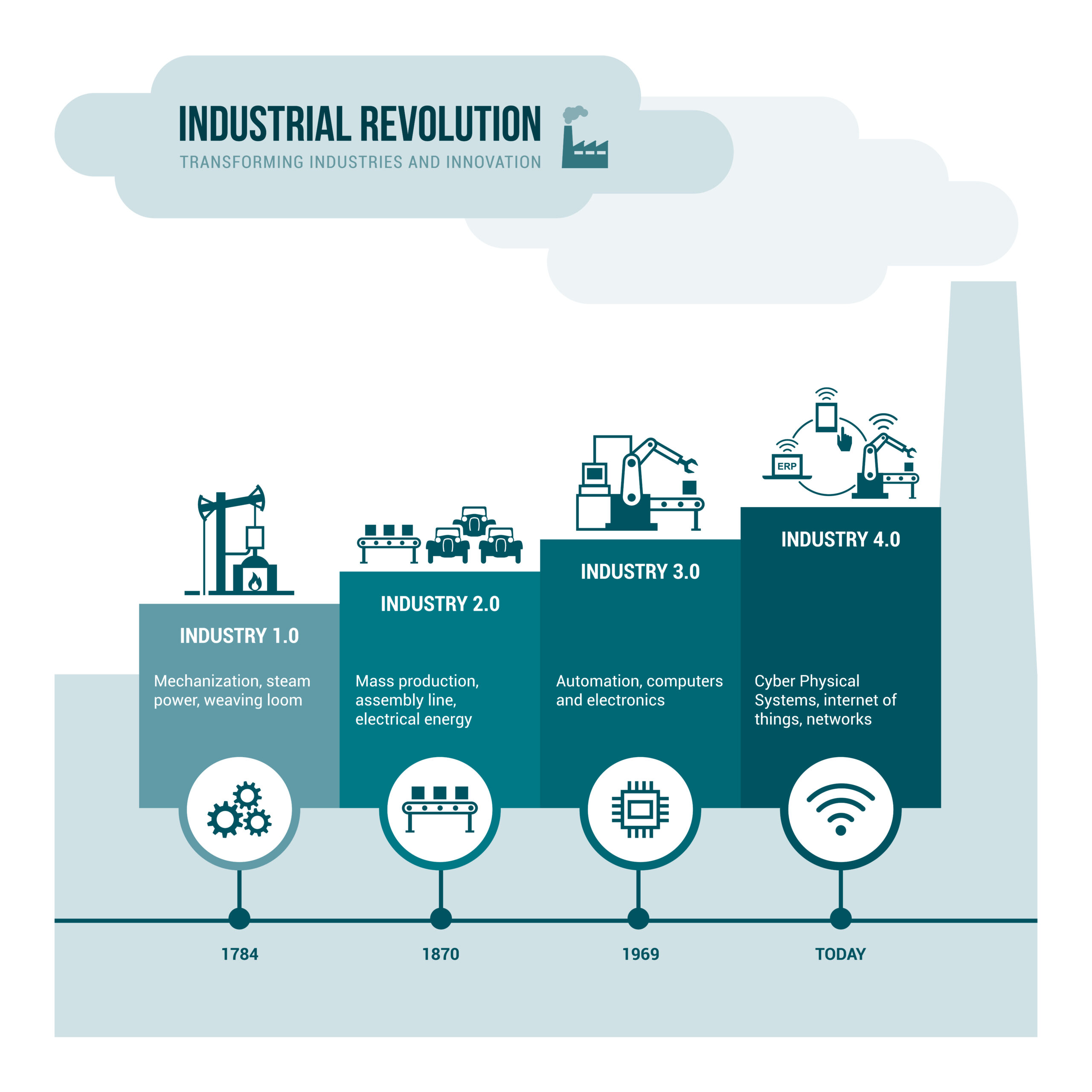
Abb. 2: Das viel gesehene Bild der industriellen Revolutionen neu erklärt
Industrie 4.0 nach Abb. 2 bedeutet auf einen zentralen Nenner gebracht «Effizienzsteigerung der Produktion und Logistik auf der Grundlage von Daten». Gegenüber IIoT ist Industrie 4.0 ein erweiterter Begriff aus dem deutschsprachigen Raum, der die Daten-Intelligenz verstärkt auf eine dezentrale Ebene bringt (Cyberphysikalische Systeme mit Einsatz von Künstlicher Intelligenz).
Doch sogar 12 Jahre nach Prägung des Begriffs Industrie 4.0 stehen die meisten industriellen Unternehmen, auch in der Schweiz, in der Umsetzung immer noch am Anfang. Oder positiv ausgedrückt, es schlummert weiterhin ein riesiges Potential in der noch möglichen Effizienz-steigerung industrieller Gesamtprozesse auf der Grundlage von IIoT und Künstlicher Intelligenz.
Es besteht Grund zu fragen: Wenn das Potential der Effizienzsteigerung so hoch sein soll, warum geht es denn nicht schneller? Das liegt aus unserer langjährigen Erfahrung daran, dass die industriellen Logistik- und Produktionsprozesse einen hohen individuellen Charakter für jedes Unternehmen aufweisen. Käufliche ERP und MES-Systeme sind Standardprodukte und leider nicht in der Lage, die Cyberebene von Industrie 4.0, also die Datenverarbeitungsebene, individualisiert abzubilden. ERP und MES für sich enthalten viele wichtige Daten, aber ist eine reine Zusammenführung dieser Daten nicht ausreichend, um die Anforderungen von Industrie 4.0 zu erfüllen. Auch hat sich die Hoffnung, dass Software-Produkte neuer Startups dies als Plug & Play anbieten, bis jetzt nicht erfüllt. Jede Produktion ist einzigartig, jede dazugehörende Cybersicht auch. Deswegen bleibt eine solche Plug & Play Lösung eine weite Zukunftsvision.
Die herkömmliche Automatisierungspyramide nach Abb.3 hat weiterhin seine Daseinsberechtigung. Aber die Datenerfassung und Datenaufbereitung bis hin zur Datenanalytik sowie die Planung und Steuerung geschehen ausserhalb dieser Pyramide auf spezifischen Datenplattformen, über die im nächsten Kapitel gesprochen wird.
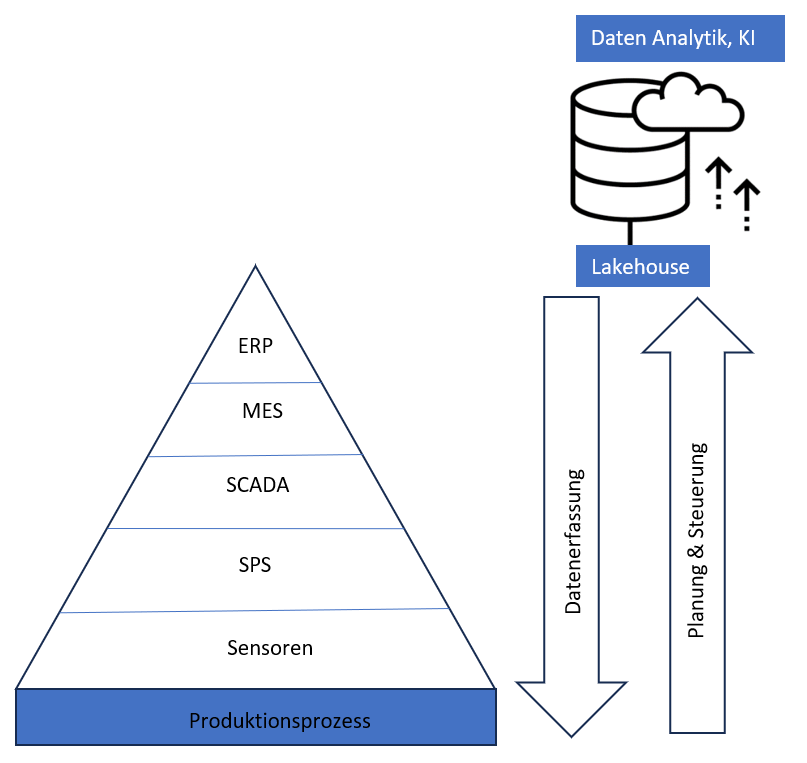
Abb. 3: Automatisierungspyramide wird erweitert durch Lakehouse
Vom Data Warehouse zum Data Lake und schliesslich zum Lakehouse
Viele Produktionsfirmen erkennen die Notwendigkeit von zentralen Datenplattformen und planen diese für die Zukunft ein. Früher sprach man vom Data Warehouse und verwendete nur strukturierte Daten. Unter Einbezug der «Realtime» Aspekte und unstrukturierter Daten wie Bilder, Audio und Texte wird heutzutage von Lakehouse gesprochen. Für ein besseres Verständnis möchte ich kurz einen geschichtlichen Abriss der unterschiedlichen Technologie von Datenplattformen geben.
Mit dem Ausbau der IT in den 90-iger Jahren erkannte man, dass auf der Grundlage von Daten bessere unternehmerische Entscheidungen möglich waren. Das waren die Anfänge von BI (Business Intelligence) und Data Warehousing. Wir selbst haben in den 90iger Jahren grosse und kleine Data Warehouses umgesetzt, auf unterschiedlichster Software und auch bereits prozessorientiert auf der Basis von Zeitstempeln. Da damals noch die Technologien für eine unstrukturierte Datenverarbeitung fehlten, wurde BI in erster Linie auf strukturieren Daten und relationalen Datenbanken aufgesetzt. Aus Gründen der Performance hat man Star- und Snowflake-Data Marts nach Kimball gebaut, häufig auch im 3-Schichten Prinzip, was aber auch zu hohen Projekt- und Betriebsaufwänden führte. Mit Grund haben KMUs die Finger von solchen Umsetzungen gelassen.
Anwendungsfälle wie Qualitätsüberwachungen auf Basis von Bildern, Rückverfolgbarkeitsbetrachtungen auf stark verteilten Daten und Verarbeitung grosser Datenmengen wie beispielsweise von Akustiksensoren lassen sich heutzutage effizient aufsetzen. No-SQL und Zeitdatenbanken sowie Plattform-Lösungen mit einem hohen Automatisierungsgrad lassen jeden erdenklichen individuellen Use Case betriebswirtschaftlich sinnvoll nutzen.
Die Firma Snowflake war ab 2012 einer der ersten, die die Automatisierung von DWHs vorangetrieben hat und durch die Reduktion von Projekt- und Betriebskosten grossen Erfolg vorweisen konnte. Business Intelligence und Data Warehousing wurde damit auch für KMUs erreichbar.
Gleichzeitig wurden aber auch Technologien geschaffen, um mit unstrukturierten Daten umgehen zu können, z.B. NoSQL Datenbanken und unterschiedlichste Tools und Formate wie bspw. Apache Spark, Deltalake und Iceberg. Mit dem Data Lake Ansatz erschlug man zwei Fliegen gleichzeitig: die Kombination strukturierter und unstrukturierter Daten sowie die gleichzeitig stark vereinfachten Datenmodelle eines Data Lake. In einer solche Umgebung wurde zum Beispiel Databricks sehr erfolgreich.
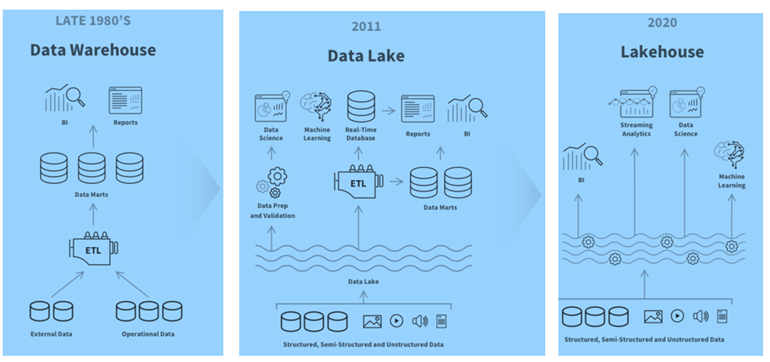
Abb. 4: Vom Data Warehouse über Data Lakes zu Lakehouse
Die Nachteile der Data Lake Lösungen erkannte man bald, denn solche Datenstrukturen sind weit weg von den Self-Service Anforderungen der Geschäftsbereiche. Die Geschäftsbereiche wurden ungewollt abhängig von zentralen Datenkompetenzen der IT, obwohl man versuchte, diese eng an das Business anzuschliessen.
Das Streaming von Daten wurde wie oben beschrieben für Realtime Lösungen immer wichtiger und gleichzeitig sollte der Self-Service Ansatz für die Geschäftsbereiche wieder stärker ins Zentrum gestellt werden. Das Konzept des Lakehouse war geboren. Die bisher erfolgreichen Softwareanbieter wie Microsoft, Snowflake und Databricks entwickelten sich dann in Richtung Lakehouse weiter- mit teilweise unterschiedlichen Architekturen.
Um noch einen dritten Plattformanbieter im Bereich Lakehouse zu nennen: Erst vor kurzem wuchs Dremio zu einem Einhorn heran und bietet im Moment noch eine lizenzfreie Einsteigerlösung an. Dremio ist ausgerichtet auf die Datenabfrage (Data Engine mit Caching).
Eine klare Aussage zu den Gesamtkosten für ein Unternehmen beim Einsatz einer dieser vier erfolgreichen Lösungen ist nur möglich, wenn die spezifischen Anforderungen geklärt sind. Wir raten diese vorgängig toolunabhängig aufzunehmen, wobei wir beim nächsten Thema wären: der Umsetzung. Wie diese erfolgreich in Angriff genommen werden kann erläutern wir in Teil 2 dieses Artikels.

- Blog: Braucht Industrie 4.0 ein Data Warehouse oder ein Lakehouse? (Teil 2) - Januar 17, 2024
- Blog: Braucht Industrie 4.0 ein Data Warehouse oder ein Lakehouse? (Teil 1) - Januar 17, 2024
- Zusammenschluss Substring und LeanBI - Dezember 31, 2023