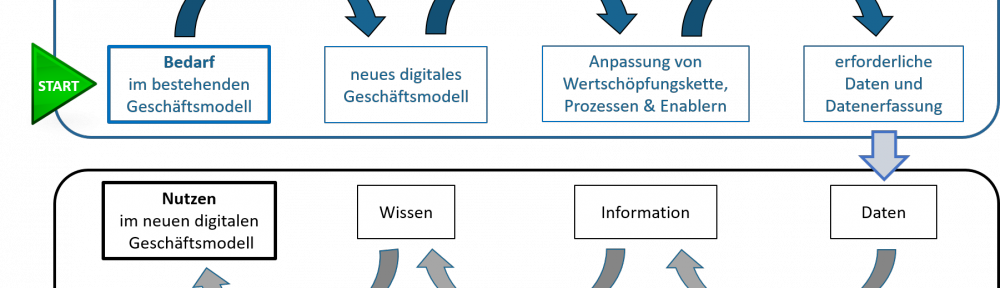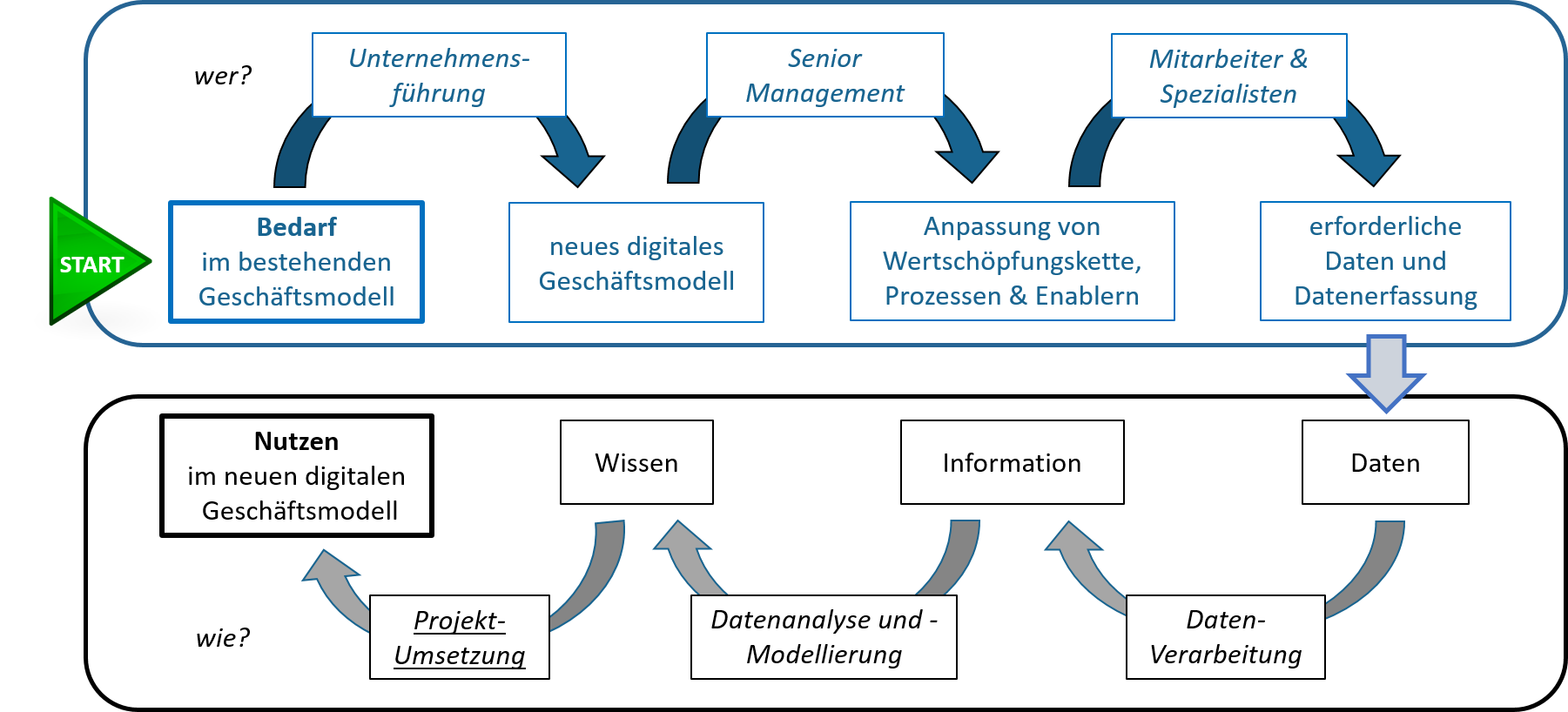
In diesem letzten Artikel unserer Ananomalierkennungs-Serie zeigen wir ein praktisches Beispiel der Anomalieerkennung. Wir erklären, in welchem Szenario der Anomalieerkennung wir uns befinden und welche Anomalien wir in Betracht ziehen. Mehr Einzelheiten erfahren Sie in den vorhergehenden Artikeln zum selben Thema: „Die drei verschiedenen Arten von Anomalieerkennung“ und „Die drei Szenarien der Anomalieerkennung“.
Es handelt sich um einen Elektromotor. Dieser dreht mehrere durch einen Antriebsriemen miteinander verbundene Metallscheiben. Die einzelnen Teile des Motors und die Scheiben vibrieren, wenn der Motor läuft. Die Vibrationen werden mit einem drahtlosen Vibrationssensor der Firma Neratec gemessen. Diese Messungen ermöglichen die Erkennung möglicher Anomalien des Motors.
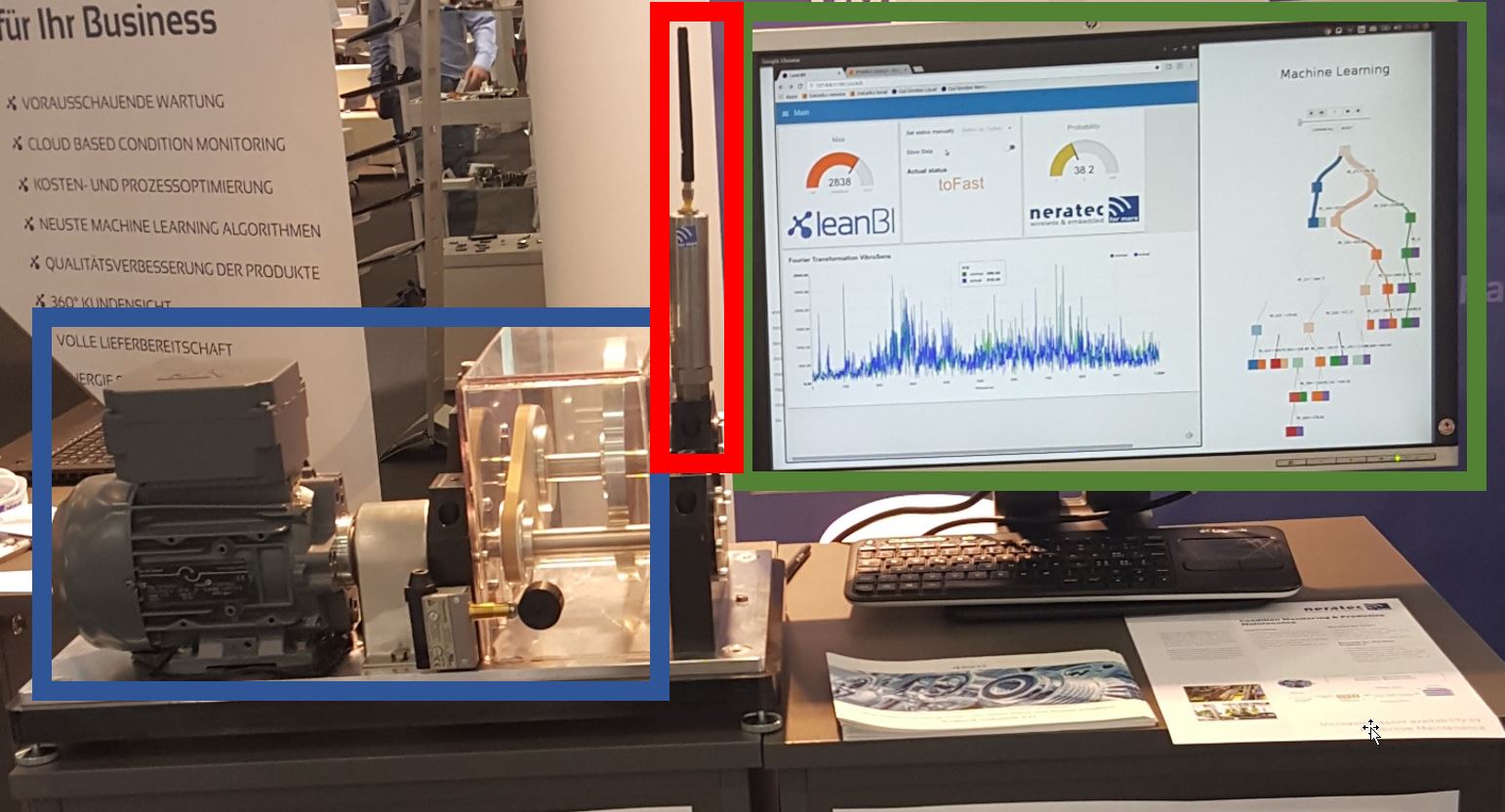
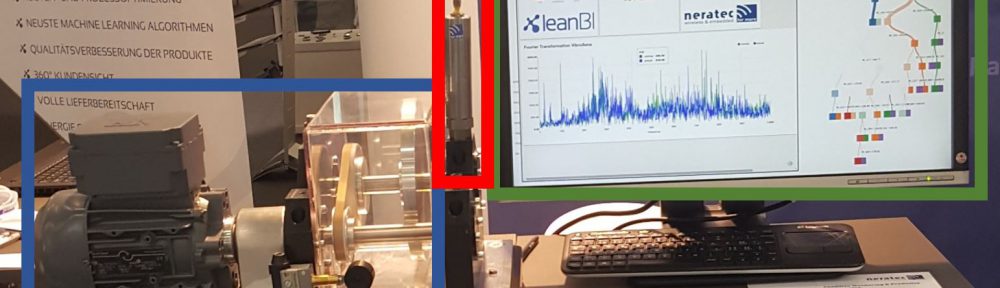
Abb. 1: Elektormotor an unserem Stand auf der SINDEX 2016 in Bern. Blau: Motor. Rot: Vibrationssensor. Grün: Echtzeitanomalieerkennung.
Die vollständige Anlage ist in Abb. 1 dargestellt. Der Motor ist blau, der Vibrationssensor rot und die Benutzeroberfläche grün umrahmt. Wir haben diese Versuchsanordnung bei der großen, alle zwei Jahre stattfindenden Technologiemesse Sindex 2016 aufgebaut.
In den nächsten Kapitteln gehen wir in wenigen Zeilen auf die Einzelheiten der Problemerkennung, Problemlösung und Durchführung der Anomalieerkennung ein.
Problemerkennung:
Die Hauptursachen von Funktionsstörungen eines solchen Motors sind folgende: Der Motor dreht sich zu langsam, zu schnell oder eine der Metallscheiben ist in Unwucht. Weitere Funktionsstörungen haben wir absichtlich außer Acht gelassen, da sie mit einem Vibrationssensor nicht von anderen Störungen unterscheiden lassen. Ein Problem der Stromversorgung beispielsweise, verhindert, dass der Motor läuft: Wie wäre ein Stromunterbruch vom ausgeschalteten Motor mit einem Vibrationssensor zu unterscheiden?
Wir wollen herausfinden, ob der Motor richtig funktioniert und die verschiedenen Anomalien erkennen. Wir haben also ein Klassifizierungsproblem mit fünf Klassen:
- 1. Der Motor ist ausgeschaltet
- 2. Der Motor funktioniert normal
- 3. Der Motor läuft zu langsam
- 4. Der Motor läuft zu schnell
- 5. Eine der Metallscheiben ist in Unwucht
Im Vorfeld haben wir Messungen jeder Klasse vorgenommen und jede Messung einer der fünf Klassen zugeordnet. Dadurch sind die zu erkennenden Anomalien vollständig bekannt.
Problemlösung:
Die zur Verfügung stehenden Daten werden durch den Vibrationssensor gesammelt. Dieser stellt ein Signal mit 2 kHz Abtastrate zur Verfügung. Dieses Signal haben wir mittels Fast Fourier Transformation (FFT) in den Frequenzbereich transformiert. Die Features (verwendete Merkmale) unseres Modells sind somit die Koeffizienten der Fourier-Transformierten.
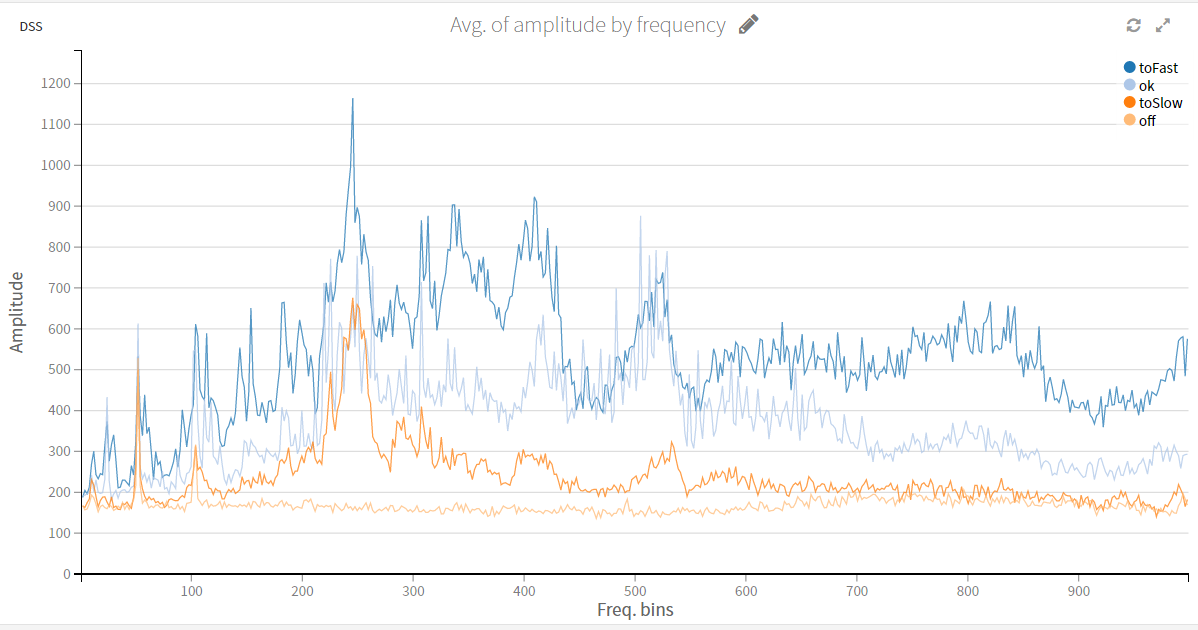
Abb. 2: Mittlere Frequenzen je nach Zustand des Motors (ausgeschaltet, normal, zu schnell, zu langsam)
Im vorliegenden Beispiel haben wir mehrere Modelle angewandt und getestet. Unser Ziel war es, richtige Vorhersagen schnell und mit einem einfachen Algorithmus zu erhalten. Unsere Wahl fiel schließlich auf den Algorithmus Random Forest. Er ist einfach anzuwenden, schnell, erzielt zufriedenstellende Ergebnisse und gibt Auskunft über den Einfluss der verschiedenen Features (Merkmale) auf die Anomalienklassifizierung.
Durchführung:
Das Projekt wurde mit der Software Dataiku durchgeführt. Es erleichtert und beschleunigt Datenimport, -bereinigung und -verarbeitung. Auch das Erstellen eines Modells ist einfacher. Unseren Algorithmus Random Forest können wir mit einem einzigen Klick anwenden und auswerten.
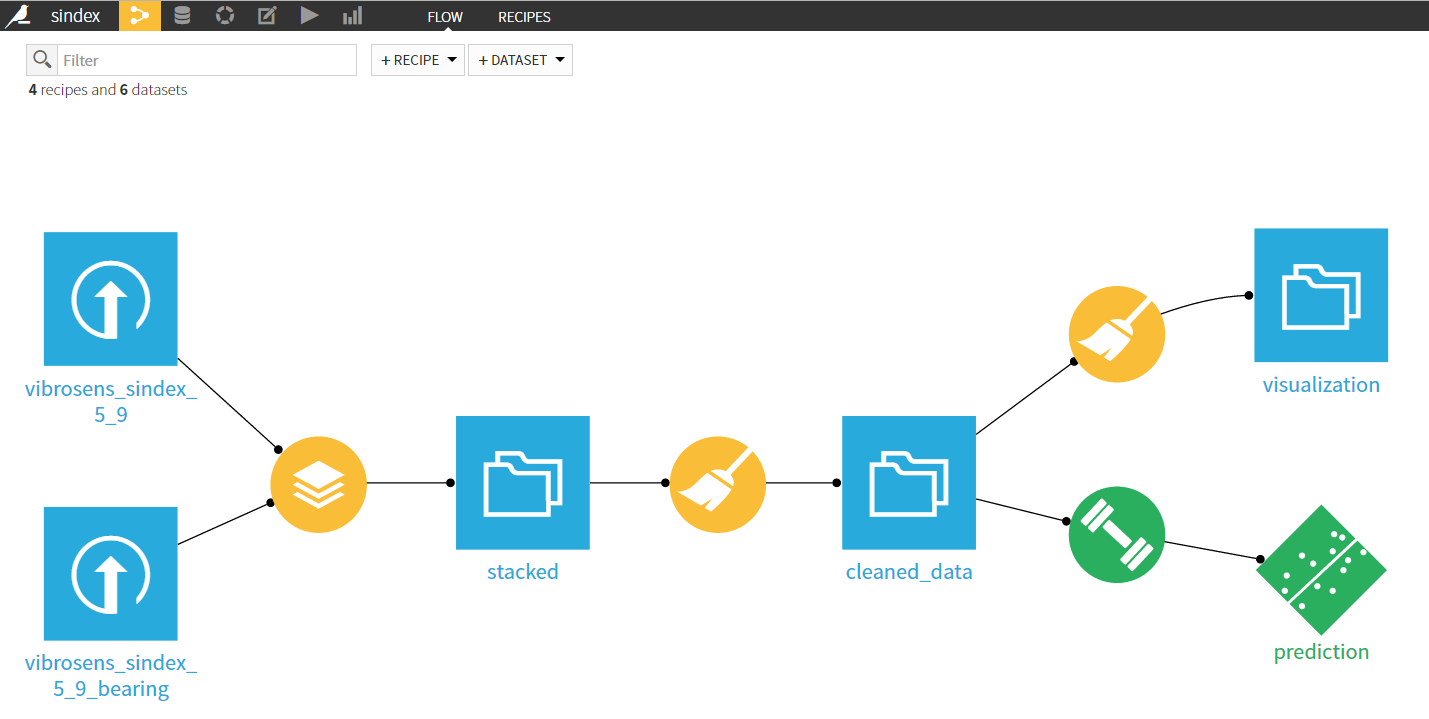
Abbildung 3: Datenfluss des Projekts in Dataiku
Abschließend ein kurzes Video, das auf der SINDEX aufgenommen wurde, und in welchem wir unseren Motor live vorstellen: