Explication claire : Procédé technique de l’analyse prédictive sur l’exemple concret du « stockage de la bière »
Lors d’une analyse prédictive, des données actuelles et archivées sont analysées statistiquement afin de prédire des résultats (la plupart du temps dans le futur) à partir des connaissances acquises. Les prévisions sont des statistiques du type suivant: il y a une probabilité de 90% que la consommation de bière augmente début août 2016 de 21% à Rio et de 25% à Berne. Aujourd’hui même l’analyse prédictive est utilisée :
- Maintenance prédictive: Il est possible de prédire à quel moment une panne peut survenir -> l’entreprise de maintenance peut agir à l’avance
- Satisfaction de la clientèle : Une entreprise anticipe la satisfaction de la clientèle -> Les problèmes du client sont résolus de façon proactive -> le client reste fidèle
- Cote de crédit : La banque estime la probabilité qu’un débiteur rembourse son crédit à temps -> Elle décide si le crédit est octroyé ou non
- Prévision policière : À Zürich, les cambriolages sont anticipés -> Les effectifs de police sont déployés au bon endroit et au bon moment
Un projet d’analyse prédictive fructueux est composé de trois éléments clés. Nous allons nous concentrer dans ce billet de blogue sur la mise en œuvre de ces trois éléments.
- Accès aux données pertinentes
- Une question à laquelle on peut répondre avec l’aide des données
- Une mise en œuvre technique avec des algorithmes et des modèles
Vue d’ensemble du procédé
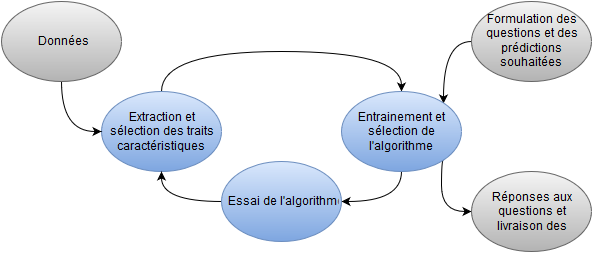
Figure: Procédé d’analyse prédictive des données à travers les processus d’extraction et de sélection des traits caractéristiques.
Il est ici essentiellement question de savoir de quelle façon une certaine information doit être traitée avant d’être utilisée (extraction) et, compte tenu des données existantes, quelles informations doivent être tout particulièrement utilisées (sélection). Les critères ainsi extraits et sélectionnés sont ensuite traités par un algorithme, lui-même entrainé à partir d’anciens résultats. Comme représenté sur la figure, il s’opère ensuite une étape d’optimisation, durant laquelle les meilleurs critères sont mis à disposition tandis que ceux qui ne peuvent pas aider plus l’algorithme sont supprimés. Différents algorithmes sont ainsi testés jusqu’à ce qu’une prédiction satisfaisante émerge. Ensuite, l’algorithme le plus adéquat est mis en service, afin de fournir des prédictions de bonne qualité à partir de nouvelles données. Nous allons maintenant vous présenter de façon plus détaillée les différents points.
Extraction des traits caractéristiques
Il est par exemple possible d’extraire beaucoup d’informations à partir d’une date : on peut savoir quel est le jour de la semaine associé, si elle correspond à une fin de semaine, à une période de vacances scolaires, au déroulement des Jeux olympiques, ou si elle est proche du 1er aout. En fait, toutes ces informations peuvent être pertinentes après réflexion : fin de semaine -> plus de temps pour boire, 1er aout -> plus grand chiffre d’affaire sur la vente au détail le jour précédent, Jeux Olympiques -> plus grande consommation de bière, etc. Ainsi, l’extraction des traits caractéristiques peut contribuer de façon décisive à un algorithme destiné à prédire la demande de bière.
Sélection des traits caractéristiques
La sélection des traits caractéristiques est également importante. Il existe une foison de données différentes. Il serait ainsi mal avisé de mettre à disposition de l’algorithme toutes les données existantes, dans la mesure où cela peut mener à ce qu’on appelle un « overfitting » (littéralement : « surapprentissage » en français). Par exemple, le fait que le Marché aux Oignons de Berne se soit déroulé le 23 novembre 2015 a certes une forte influence sur la consommation de vin chaud, mais ne nous apprend rien concernant la consommation de bière ; cette information risque donc de porter à confusion et l’algorithme doit désormais apprendre qu’il ferait mieux de l’ignorer. Il se peut que l’algorithme accorde trop d’importance à certains traits de données pourtant insignifiants, et fournisse ainsi des prédictions imparfaites.
Une question de quantité de données
On peut totalement déléguer à un ordinateur les tâches d’extraction et de sélection des traits carctéristiques. Ces tâches fonctionnent sans intervention humaine, à condition que les quantités de données soient suffisamment grandes et qu’il existe une capacité de calcul suffisante. Un algorithme découvre ainsi sans problème que les derniers Jeux olympiques d’été à Londres ont relancé la consommation de bière et que ce n’était pas un cas isolé (les Jeux olympiques précédents ont également mené à une augmentation de la consommation de bière).
Ainsi, un ordinateur peut trouver de lui-même et sans intervention humaine le critère « Jeux olympiques ». Cela ne fonctionne évidemment que si les données existent sur la période des derniers Jeux olympiques (15-20 dernières années), ce qui suppose d’une part d’avoir une base de données suffisante (le plus souvent Big Data) et d’autre part d’aller de pair avec de grandes puissances de calcul (jusqu’à présent dans des centres de données comme Google). L’overfitting perd de son ampleur lorsque de grandes quantités de données et des hautes puissances de calcul sont utilisées. Si l’on n’a ni la puissance de calcul ni la quantité de données requises à disposition, il faut au moins qu’une partie du traitement soit faite par des hommes (mais si possible pas le 1er aout).
La visualisation de données est particulièrement adaptée pour juger des bons critères. Les visualisations permettent de mieux discerner et comprendre les données, et peuvent également fournir des indices pour savoir s’il existe une relation entre un trait caractéristique et la prédiction dont on a besoin. On pourrait concrètement confronter un critère possible avec la prédiction souhaitée (par exemple la consommation de bière et la production de bière). On constaterait alors que la production de bière diverge avec un rythme de 7 jours de sa consommation, dans la mesure où la bière est simultanément peu produite et bien plus consommée en fin de semaine. Et c’est ainsi qu’un bon scientifique des données proposerait de choisir la fin de semaine comme trait caractéristique. Pour un projet de taille moyenne, il est plus judicieux de mettre en œuvre une combinaison d’extraction et de sélection humaines et automatiques des traits caractéristiques. En étant capable de distinguer les traits importants, non importants et trompeurs, l’homme simplifie le travail de l’ordinateur. L’algorithme peut désormais reconnaitre de lui-même les traits caractéristiques restants. Avec des traitements automatisés en nombre modéré, le volume de calcul et le danger d’overfitting se réduisent.
Choisir et entrainer des algorithmes d’apprentissage automatique
Les données et traits caractéristiques sélectionnés vont désormais être utilisés à des fins de formation de l’algorithme. L’algorithme apprend désormais à partir de l’expérience acquise, entre autres à quel point les Jeux olympiques d’été ont augmenté la consommation de bière. Les ordinateurs peuvent donc aussi estimer l’influence des Jeux sur la consommation de bière et prédire une augmentation de celle-ci le 10 août 2016, dans la mesure où les Jeux olympiques se dérouleront alors à Rio. Naturellement, cet apprentissage ne se fait pas sur un seul trait isolé (les Jeux Olympiques), mais plutôt avec beaucoup d’autres traits simultanément sélectionnés (Jeux olympiques, fin de semaine, 1er aout, Coupe du monde de football, fête de la bière, prévisions météorologiques, période de l’année, le Gurten Festival, etc.). L’enjeu est désormais de savoir quel algorithme d’apprentissage automatique doit être utilisé. Nous présentons ci-dessous quelques exigences importantes de l’algorithme :
- Précision requise: Il n’est parfois pas nécessaire d’avoir une prévision très précise. Dans ce cas, des algorithmes relativement imprécis mais aux calculs plus rapides peuvent être mis en œuvre.
- Quantité de données disponibles : Un algorithme avec peu de paramètres peut être utilisé sur de petites quantités de données. Lorsque la quantité de données à disposition est plus importante, des algorithmes admettant plus de paramètres et ainsi plus complexes, précis et exigeant davantage de calculs sont possibles.
- Algorithmes explicatifs : il peut arriver que l’on souhaite une explication supplémentaire à propos d’une prévision. L’algorithme doit par exemple signaler que la prévision de la consommation de bière est très haute, car à cette période se déroule les Jeux Olympiques à Rio. Beaucoup d’algorithmes d’apprentissage automatique n’en sont pas capable.
- Algorithmes individuels : Les algorithmes ne sont pas encore tous programmés dans les librairies et les programmes les plus couramment utilisés. L’investissement nécessaire pour programmer soi-même un algorithme ou utiliser une nouvelle librairie peut être très important. C’est pourquoi il y a un certain attrait à utiliser des algorithmes déjà existants.
Dans la pratique, il arrive qu’aucun algorithme ne remplisse toutes les exigences, en particulier lorsque l’algorithme « parfait » n’est pas implémenté dans les outils utilisés. C’est pourquoi il est raisonnable de commencer avec un algorithme plus simple aux calculs rapides et immédiatement accessible. Si un tel algorithme n’est pas capable de fournir une prévision approximative raisonnable, il est peu probable qu’un algorithme plus raffiné en calcule une meilleure. Dans ce cas, il est plus fructueux d’utiliser par exemple des données supplémentaires et de meilleurs critères. Lorsqu’il est toutefois nécessaire d’améliorer légèrement la qualité de la prédiction d’un algorithme simple, des algorithmes plus raffinés peuvent être d’un grand secours. Ainsi, de meilleurs algorithmes et traits caractéristiques peuvent être recherchés étape par étape.
Tester les algorithmes d’apprentissage automatique
Il n’est pas seulement nécessaire d’utiliser des données pour calibrer un algorithme, mais aussi pour le tester ou, autrement dit, mesurer sa qualité. C’est pourquoi les données existantes sont séparées en deux groupes. L’algorithme est entrainé à l’aide du premier groupe, nommé « données d’entrainement », et testé à l’aide du second, nommé « données de test ». Lors d’un test, l’algorithme sera chargé de fournir une certaine prédiction. Les résultats de cette prédiction seront ensuite comparés avec les mesures réelles des données de test. On peut alors considérer que l’algorithme a bien réussi si les prédictions correspondent aux mesures réelles. Je voudrais dire encore quelques mots au sujet de la répartition des données entre les groupes d’entrainement et de test. La répartition doit s’effectuer aussi réalistement que possible, afin de ne pas induire le test en erreur. Par exemple, un test réaliste sur la demande de bière devrait être réalisé comme si l’on était le mois dernier. On entraine ainsi l’algorithme avec les données existantes du dernier mois. Par la suite, l’algorithme entrainé fournit les prédictions souhaitées dans le futur (donc pour le mois en cours). La prédiction est désormais comparée avec les valeurs mesurées du mois en cours.
Répondre aux questions / faire des prédictions
Désormais, les traits caractéristiques sont choisis et l’algorithme est entrainé, et ainsi les prédictions souhaitées peuvent être fournies mécaniquement. La production sait donc, par exemple, quelle quantité de bière doit être produite. La logistique peut également être optimisée, dans la mesure où l’on sait où et en quelle quantité la bière sera demandée. Les prédictions sont heureusement réalisées automatiquement, et il vous restera donc assez de temps pour regarder les Jeux olympiques avec votre bière favorite en main.
Questions
Écrivez-nous si vous avez des questions ou si vous souhaiter assister à une démonstration en direct (info@leanbi.ch), ou bien appelez-nous au +41 79 247 99 59.
- TensorFlow - mai 29, 2017
- Moteur rotatif – exemple de détection d’anomalies - avril 4, 2017
- Les 3 scénarios de détection d’anomalies - mars 15, 2017