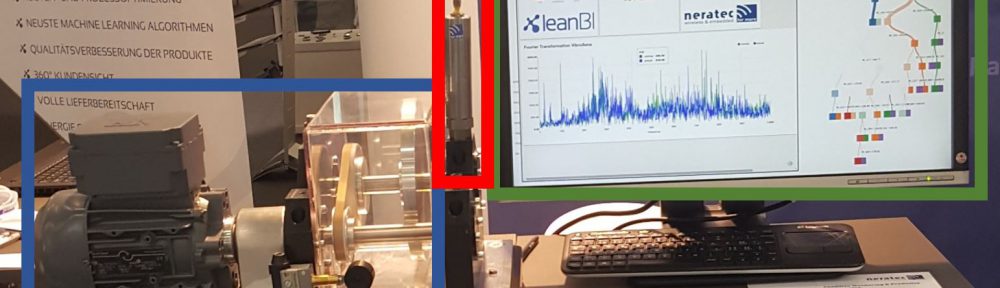
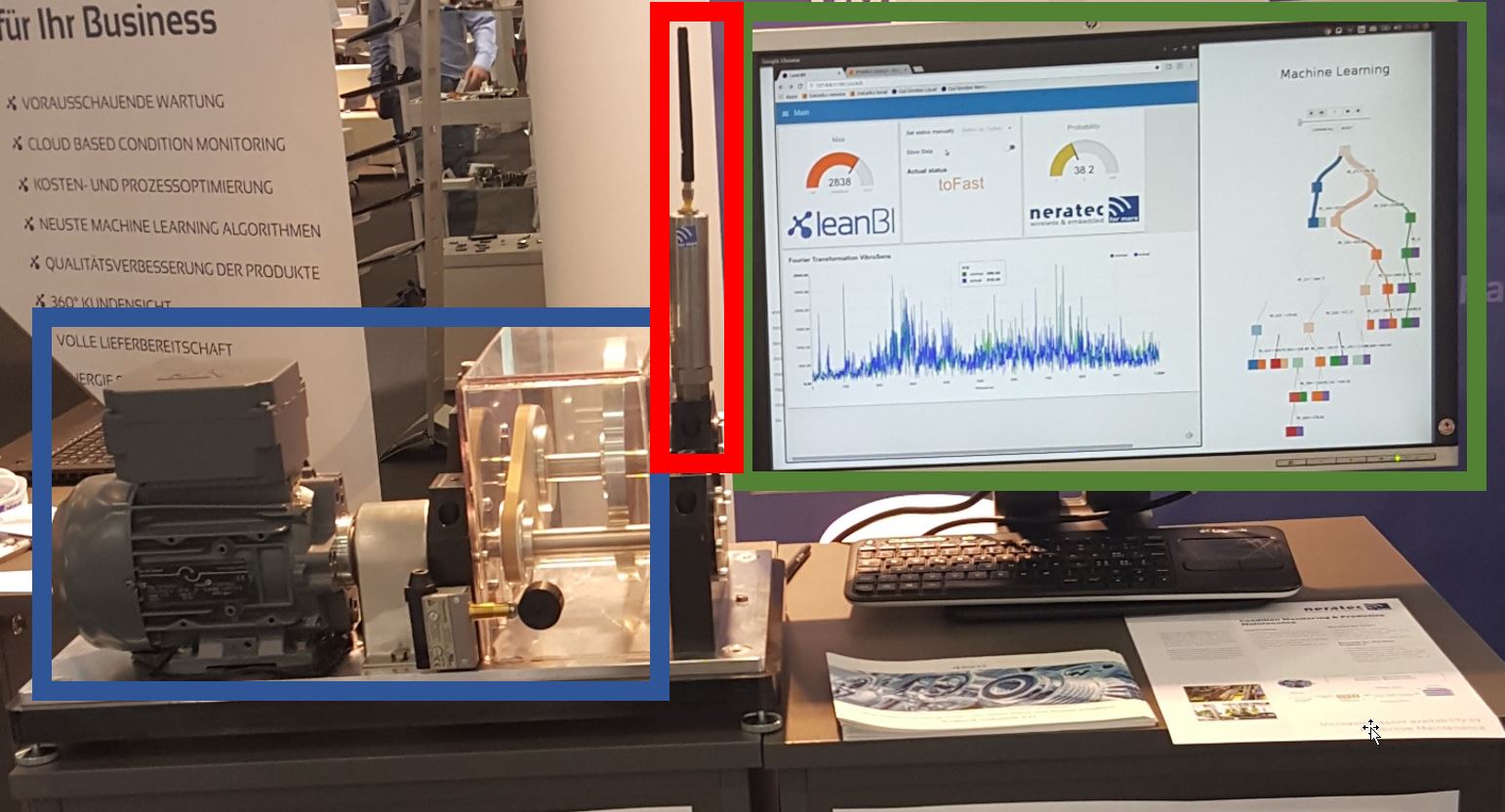
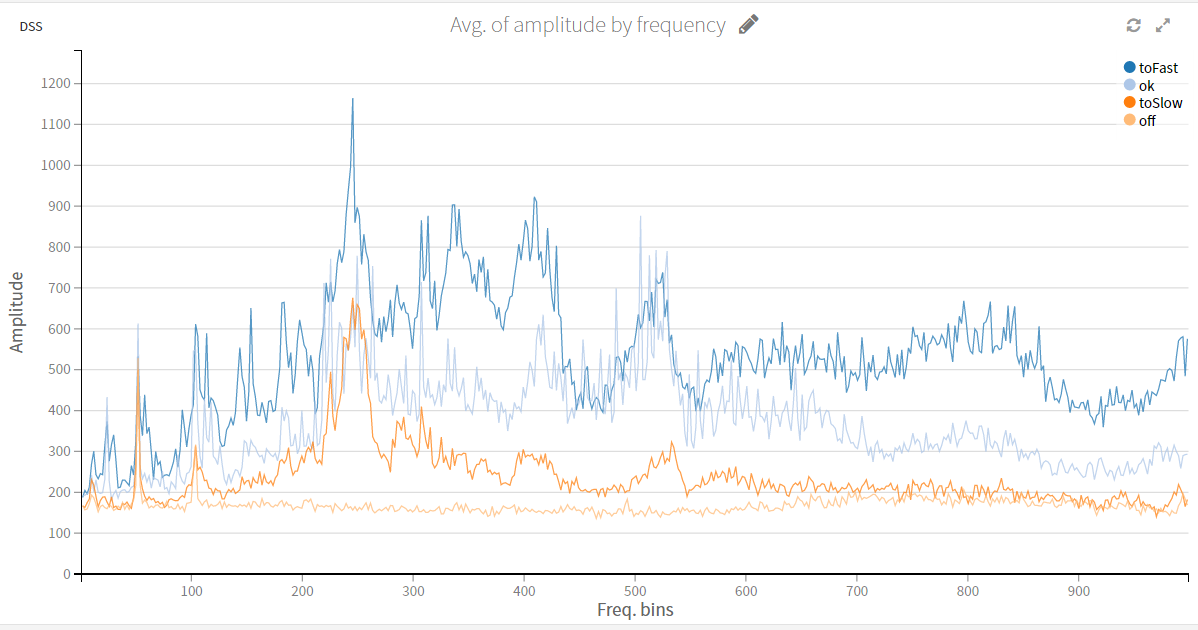
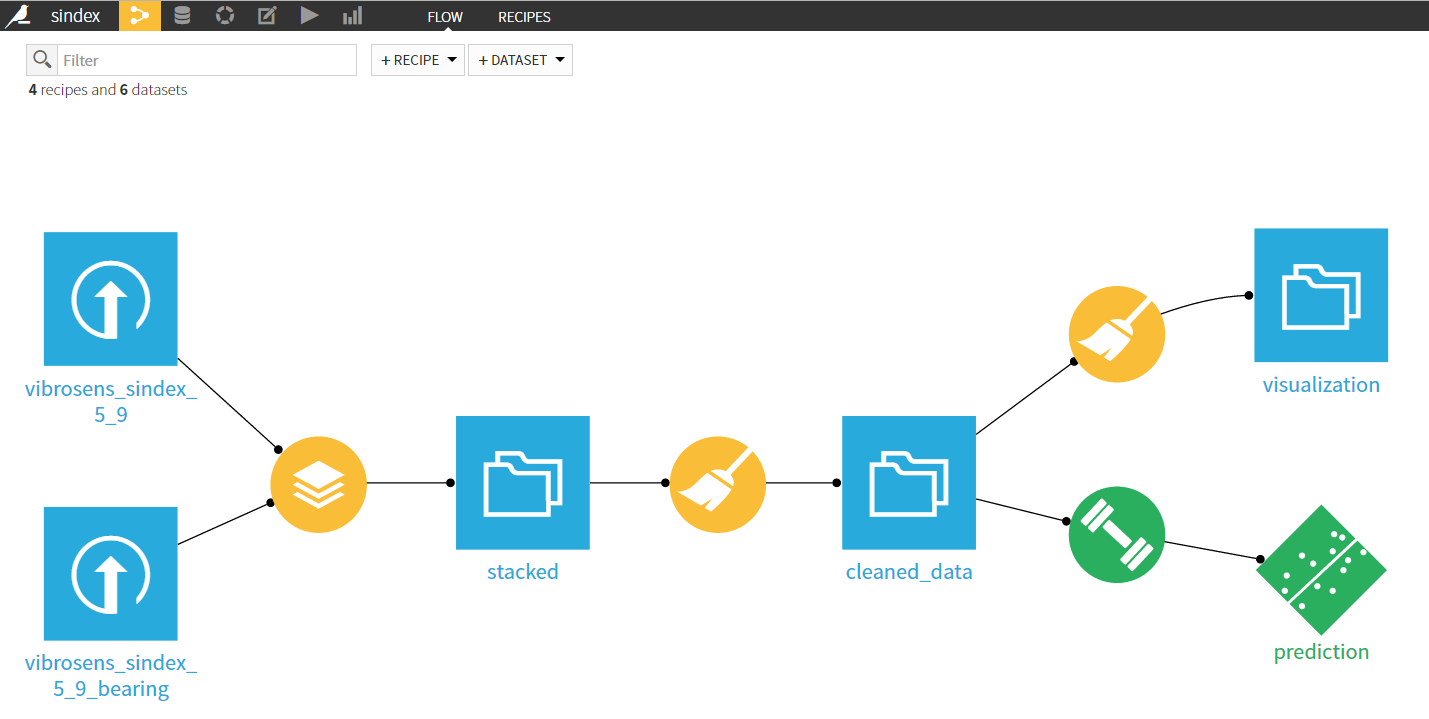
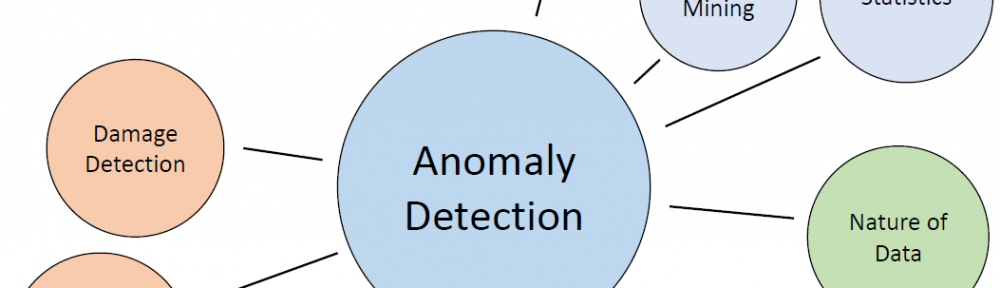
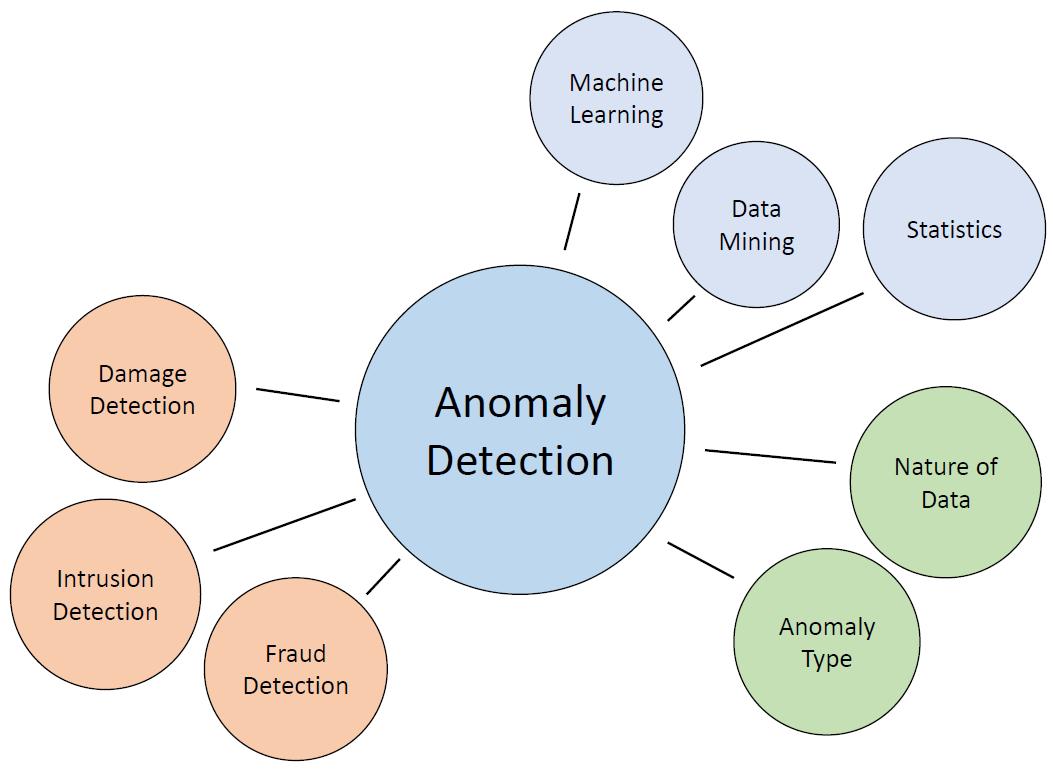
LeanBI ist konstant auf der Suche nach neuen Technologien um innovative Geschäftsmodelle zu entwickeln und neue Projekte zu starten. Eine solche Technologie präsentieren wir in diesem TensorFlow Blog.
Was ist TensorFlow
TensorFlow ist eine plattformunabhängige und freie Programmbibliothek für künstliche Intelligenz bzw. maschinelles Lernen. Es ist der Nachfolger von DistBelief, eine ähnliche aber nicht freie Programmbibliothek von Google. TensorFlow wird vor allem für die Modellierung neuronaler Netze benutzt. Im Moment sind Sprach- und Bildverarbeitungsaufgaben die Hauptanwendungsfälle. Andere Nutzungen sind aber möglich.

Wie funktioniert TensorFlow?
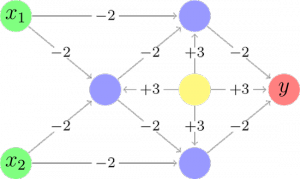
TensorFlow führt numerische Berechnungen durch gerichtete Datenflussgraphen aus. Die interne Struktur von TensorFlow ist wie folgt:
- Die Tensoren sind Objekte bzw. Datenstrukturen, die Vektoren oder mehrdimensionale Matrizen enthalten.
- Die Knoten des Datenflussgraphen entsprechen mathematischen Berechnungen (Operatoren).
- Die Kanten des Datenflussgraphen entsprechen den Tensoren und geben diese an andere Knoten weiter.
Was sind die Vorteile von TensorFlow?
Im Unterschied zu Numpy ist TensorFlow für Machine Learning spezifische Berechnungen optimiert. Ein Beispiel ist die Ableitungen von Matrizen. Die dezentralisierte Architektur von TensorFlow ermöglicht die Berechnung auf mehreren Rechnern oder Grafikprozessoren.
Des Weiteren ist transferlernen (Englisch: transfer learning) möglich: Vortrainierte Modelle werden verwendet um die Merkmale neuer Datensätze automatisch extrahieren zu können. Eine praktische Möglichkeit um neuronale Netze zu benutzen ohne über grosse Datensätze und lange Trainingszeiten zu verfügen. Beispielsweise kann ein neuronales Netz, welches die Klassifizierung von LKWs gelernt hat, nach kurzem Training auch PKWs klassifizieren.
![]()
Schliesslich ermöglicht TensorFlow die Kreation, Modifikation und Ausnutzung von Neuronalen Netzen in einer vereinfachten Form. Diese Modelle sind oft komplex und dementsprechend profitiert man von bereits geleistetem Programmieraufwand. Die Verschiedene Programmierungsbibliotheken – inkl. Python die wir für unsere Teste verwendet haben – sind sehr einfach und effizient.
Möchten Sie TensorFlow spielerisch ausprobieren? Dann empfehlen wir Ihnen die folgende TenorFlow Homepage mit einem graphischen interaktiven neuronalen Netz.