IoT and Predictive Analytics: Fog and Edge Computing for Industries versus Cloud (19.1.2018)
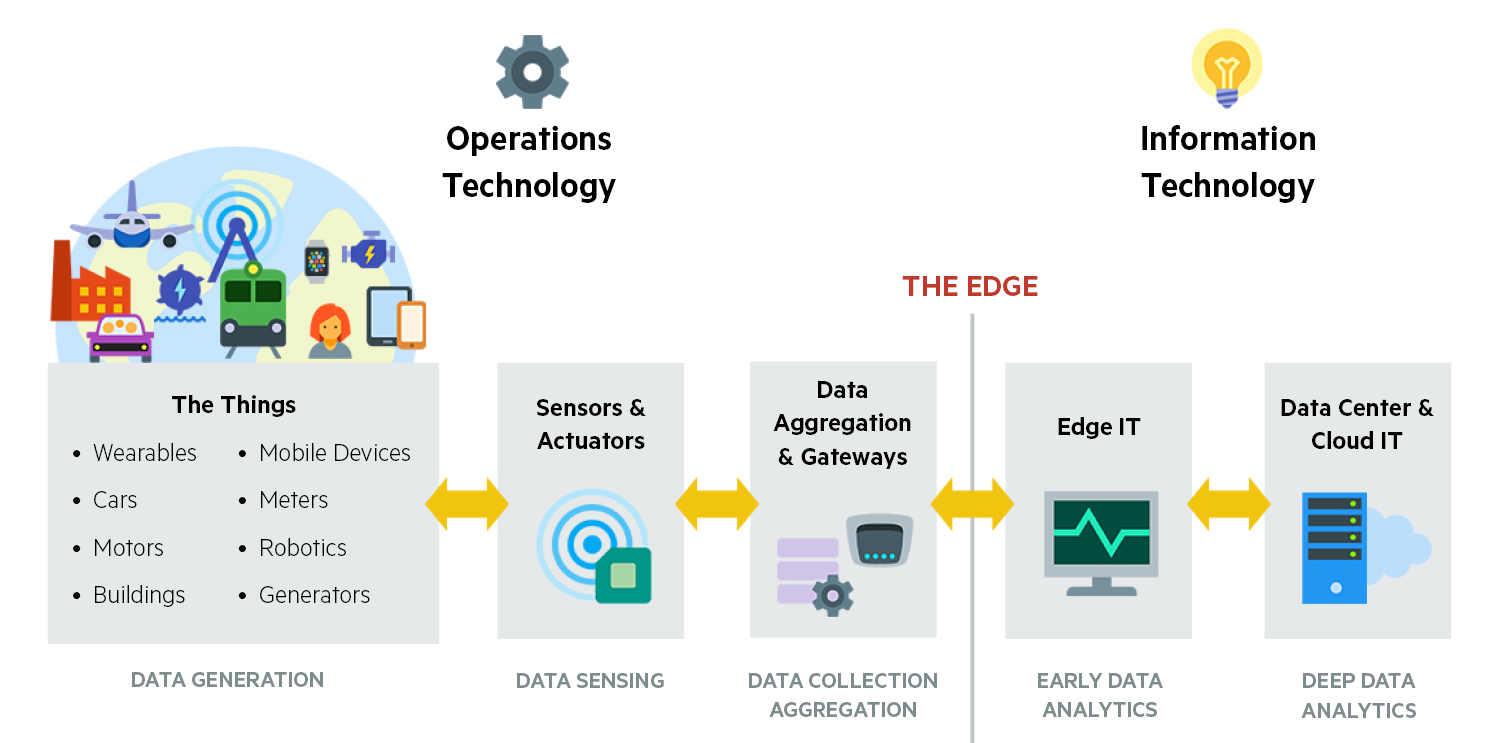
Image: ESG Research 2016
Why it doesnt always have to be the Cloud?
Our industrial customers repeatedly doubt whether Cloud is really the right way to implement IoT and Predictive Analytics in industrial processes, production facilities and machinery. There are some compelling reasons for preferring it and at the same time there are also counter-arguments:
IoT und Predictive Analytics in the Cloud: Arguments in favor?
- Processes can be centrally monitored from the Cloud. With data, processes can be optimized to run better. The information from the processes can also flow into product development.
- Data is stored centrally in a database in Cloud and can be extensively used for future analyses (Data Pool, Single Source of Truth).
- Complex algorithms with large amounts of data can be executed on heavy Big Data infrastructures (e. g. Hadoop or MPP-Massive Parallel Processing infrastructures). There are no limits to CPU and RAM.
- Data can be exchanged between “Things” via a central unit. This entails a structured exchange of information (in contrast to the so-called Spaghetti network).
- The issue of data security can be centrally tackled and you don’t have to separately deal with each unit.
IoT and Predictive Analytics in the Cloud: Counter-arguments?
- Data leaves the network of the industrial process (for example, the manufacturing process), which is not acceptable to every customer. There is a potential risk of process know-how getting leaked.
- The Cloud can be used to attack the company’s data or even the systems themselves (Cyber Security). A central element such as the IoT platform of a large provider is larger and more familiar; therefore the interest in and the risk of such a point being attacked and hacked is much greater.
- The latency time between machine and Cloud impairs intervention in the millisecond range (real time or near real time applications). Many use cases in machine learning and in the field of data analysis cannot function in this way or function only to a limited extent.
- The bandwidth of the network is often not sufficient to transfer large amounts of data.
- The network can fail and the availability of the application cannot be guaranteed. In the worst case, this can have an impact on plant availability.
- For large amounts of data, a Cloud such as MS Azure IoT, Predix, Mindsphere, Amazon AWS, Google Cloud, etc. can be very expensive as the licensing models are set up on a quantity-specific basis.
What is Edge and when is it used?
The aim of new concepts is to make devices and sensors in the Edge (industrial systems) or in the Fog (i. e. in the industrial network) more intelligent to make communication move not only from and to the Cloud, but – where appropriate – between the devices themselves.
Then why not run the applications like Predictive Maintenance directly on the machine? Micro-controllers can be used, but they are limited in terms of memory and RAM. Such small processor units are used on Raspberry Pi’s, Onion Omega 3 or similar products that provide small and cost-effective IoT environments. These units have important interfaces such as WiFi, Bluetooth and USB, but their performance is rather small. For example, a Raspberry Pi Zero W has 1 GHz CPU and 512 MB storage at a price of $10 per unit.

Figure 1: Micro Controllers und Raspberry Pi‘s
The algorithms must be made very “light” in order to run on these systems and it is often not possible.
So what is the next largest unit of Compute technology? Today, the SoC (System on a Chip) components can also be used. These have much higher power densities and require less space. These are relatively inexpensive in terms of hardware costs, but have to be specifically developed for use, which in turn entails development costs.

Figure 2: Example of a SoC technology
Such systems are used for everything ranging from mobile telephones to computing units in Cloud centres. The performances go up to 54 Cores, 3 GHz, 512 GB RAM, 1TB storage and 100 Gbps bandwidth, although with price tag of about $ 100, they are also much more expensive than the Micro Controllers and Raspberry Pi’s.
Why do we need Fog Computing?
We could of course also install a server to a machine with up to 176 Cores, 2 TB RAM and 460 TB storage. However, the hardware costs would escalate dramatically forcing us to question the cost-benefit of the machine-oriented analytical unit. This of course depends on the price of the machine itself although in many cases is probably not worth it.
Fog works with the Cloud, while the Edge by definition excludes the Cloud. Fog works hierarchically, whereas Edge is limited to a small number of layers. Besides calculation, Fog also deals with networking, storage, control and acceleration. An interesting and inexpensive intermediate solution to the Cloud can be created with Fog Computing. With Fog, computing power is pushed to the periphery of the networks and is executed for a group of “Things” between Edge and Cloud.
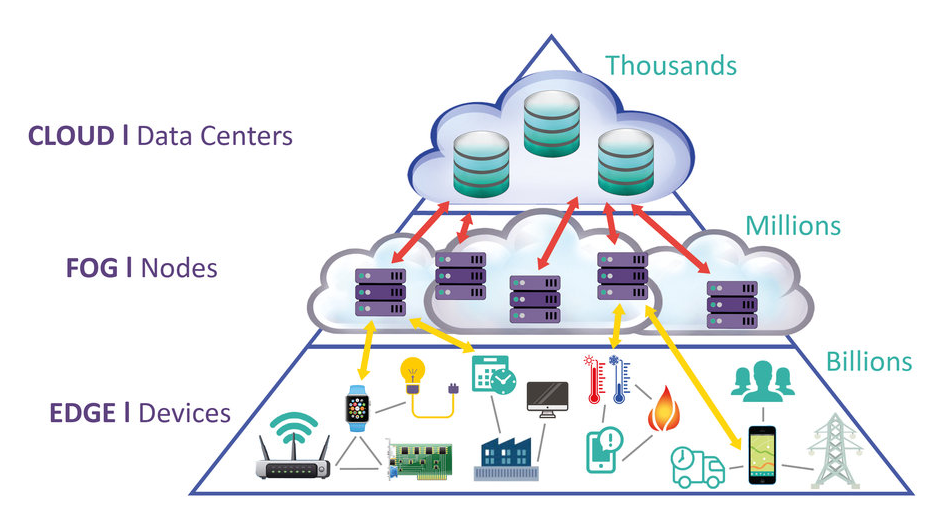
Figure 3: Representation of the Fog Architecture
Fog: An Architectural concept
Fog is first of all an architectural approach, secondly a software and thirdly a hardware component. The approach is still quite new and dates back only to 2014. In 2015 the Open Fog Consortium was founded by some important exponents such as Cisco, Intel, Dell, Microsoft and Princeton University. The first architectural concept was published In February 2017 and can be viewed here:
https://www.openfogconsortium.org/wp-content/uploads/OpenFog_Reference_Architecture_2_09_17-FINAL.pdf
The publication is not yet very concrete and you have to fight your way through 162 pages of paper. Nevertheless, a review of the document is worthwhile, and without going into it in more detail, the following collaboration of Edge, Fog and Cloud is essential for us:
The Machine Learning (ML) model is developed on a Data Science Platform. This can be done offline or in the Cloud. LeanBI uses Dataiku as a platform for this purpose. The ML Model is then exported to a productive platform. Depending on the requirements, the ML Model can run on the Edge, in Fog or directly in the Cloud. The Training-Task for Model-Optimization is usually delivered to the Cloud as this task is computationally intensive and requires a broad database. The Model is periodically optimized in the Cloud using new data and this improved Model is periodically applied to the Fog or Edge. In principle, this Training-Task can also be executed offline, depending on how often it has to take place.
Fog: One piece of software
At the moment, the software landscape around Edge and Fog Computing is still very manageable and the range of functions is sometimes very different. Cloud providers such as MS Azure IoT, Predix, AWS or IBM Watson have launched Edge/Fog Components in 2016/2017 (mostly as Open Source) to act as a link between the Edge and the Cloud. It provides functionalities that allow the Machine Learning Model to run on the Edge. Here are three examples:
AWS Greengrass: https://aws.amazon.com/de/greengrass/
Azure IoT Edge: https://azure.microsoft.com/de-de/services/iot-edge/
IBM Edge Analytics: https://console.bluemix.net/docs/services/IoT/edge_analytics.html#edge_analytics
When it comes to Data Preparation, Data Cleansing and Data Processing on the Edge/Fog, these solutions are still very complex to program. The solutions cannot be used independent of the Cloud solution. There are also some software solutions that make Edge and Fog Computing possible independent of the Cloud provider. Foghorn, a Silicon Valley start-up, is an example of this.
Foghorn: https://www.foghorn.io/technology/
Foghorn offers Data Preparation and a very fast execution engine, also known as the CEP Engine. CEP stands for Complex Event Processing and includes different methods to handle logic in real time. CEP can be operated within Docker and runs directly on the Edge. In most cases, the software does not run on the endpoints of the systems, but on the physical gateways.
Fog: A piece of hardware
The physical gateways have the advantage of software still running close to the plant, but at the same time a whole bundle of machines and plant points can be operated. In terms of networking, the software is still running in the automation network, i. e. decoupled from the Cloud, and data exchange happens over the standard connectors of the gateways. However, important data can easily be made available to the Cloud from this point.
Here are some examples that provide some impression of the performance of today’s gateways:
Hilscher Gateway „On Premise“ https://www.hilscher.com/fileadmin/cms_upload/en-US/Resources/pdf/netIOT_Edge_DS_Datenblatt_10-2015_DE.pdf

Features the important field and IoT protocols for the machines: Profibus, Profinet, Modbus, MQTT, OPC-UA and others. Performance up to 2 GHz, 4 GB DDR3 RAM and 128 GB SSD. Physical separation of automation and cloud network for security reasons.
Dell Edge Gateway der 5000 Series
http://www.dell.com/ch/unternehmen/p/dell-edge-gateway-5000/pd
As a comparison, this Dell Edge Gateway has a slightly weaker performance of 1.33 GHz, 2 GB DDR3 RAM and 32 GB SSD in the same price range of about $1000.
HP manufactures both mid-range and high-end gateways. Here is a Middle class version
HP Gateway: HPE GL20 IoT Gateway
Intel® i5 CPU, 8 GB RAM, 64 GB SDD Storage
But there is also a high-end version like the following system:

HPE Edgeline EL1000 Converged Edge System
With up to 16 cores and 4 TB disc storage which will let you run very nice analytical solutions.
Summary and conclusion
Future analytical solutions will not only be operated on the machine or in the Cloud. Instead, Fog architectures will increasingly become the appropriate solution.
Here, combination deployments of physical gateways and cloud platforms are used which is a cost-effective form of implementing analytical solutions close to the machine or system while simultaneously making optimum use of computing resources in the cloud.
What challenges remain??
- The IoT/Edge & Fog solutions are still new and currently undergoing radical development.
- It is always necessary to define which data is given in the Cloud and which data remains in the Edge and Fog.
- Storage, CPU and cost limits in the Edge/Fog.
- Modelling in one place – Execution and distribution in several locations.
- Standards for peer-to-peer solutions are not yet sufficiently available

- Merger of Substring and LeanBI - December 31, 2023
- Blog: New optimization potentials thanks to AI and physical models - July 14, 2023
- Blog: Acceleration of development through AI and physical models - June 20, 2023